



1. Introduction
The brain receives external and visceral sensory signals, extracts useful information out of them, and makes conscious or unconscious decisions on appropriate responses and actions all the time. Signal perception, decision making, and action triggering in the brain are carried out by a huge and complex network of interacting neurons, each of which integrates input signals and sends action spikes to other neurons. The brain, with a size of about 2% body mass, consumes about 20% of the body's metabolic energy, and it must be under strong evolutionary pressure to reduce energy consumption [1]. Predictive coding has been proposed as a general strategy to reduce the energy cost of information processing [2–4].
Input signals to a neural network and the internal states of the network are produced by real-world physical or chemical processes, they are far from being completely random but are rich in internal structures at many temporal and spatial scales, and there is a huge amount of regularity in their temporal and spatial structures. Regularity means redundancy and it could be exploited to facilitate information processing and to reduce energy costs. First, the signals received by spatially adjacent neurons at a given time are positively correlated, and this local spatial correlation could be exploited to reduce the magnitude of response of the receiving neurons [2]. Second, the sequence of signals received at a given neuron is locally correlated in time, and this local temporal correlation could again be exploited to make predictions about future events [5–7]. Third, similar signal patterns (e.g., faces or objects) are repeatedly received by a neural network over longer time scales, and the stable hierarchical relationship among them could be exploited to build a hierarchical internal model of the world [8–11].
Predictive coding has come to be an influential and promising framework in theoretical neuroscience for understanding information transmission and perception. It posits that the brain builds an internal model to perceive the external world (and also the visceral world), and constantly transmits prediction error messages among its constituent neurons to guide the refinement of this model. Previous theoretical studies on predictive coding have paid great attention to top-down feedback mechanisms. The system was often modelled by a hierarchical network consisting of many layers of neurons. Special neurons were introduced into the hierarchical network to compute and transmit prediction errors between adjacent layers in the network, and Bayesian inference was employed to refine a hierarchical internal model [3, 9, 11, 12]. For computational convenience, the lateral recurrent interactions between the neurons located in the same layer of the network were usually ignored in these earlier models. However, lateral interactions are ubiquitous in the biological brain. The mutual influences among the neurons in a single layer of the network strongly affect the state dynamics of these neurons in the short time scale, and they may then greatly affect perception and inference in the multi-layer network. Recent experimental and computational studies have demonstrated that the inclusion of within-layer interactions could dramatically change the performance of hierarchical neural networks (see, e.g., [13–15]). Whether special prediction error computing neurons really exist in the brain is also a widely debated issue [16].
The present work revisits the original concept of predictive coding within a single-layered neural network [2, 17–19]. We consider a first-order differential equation of neurons i responding to an external input with the help of peer neurons (equation (1 ) and figure 1). There is no need to introduce additional specialized neurons for computing prediction errors in our model. The internal state xi of neuron i serves the dual role of a prediction error, while the combined effect fi(x) of other neurons to this neuron is interpreted as a prediction (equation (2 )). The synaptic weights wij of lateral interactions from neuron j to neuron i are gradually optimized (on time scales much longer than that of the elementary response dynamics) to reduce the average squared prediction error. We implement a gradient descent algorithm to accomplish the task of synaptic weight adaption. Our theoretical derivation indicates that, as some of the synaptic weights deviate from being zero with learning, the symmetry of the synaptic weights is gradually lost (wij ≠ wji).
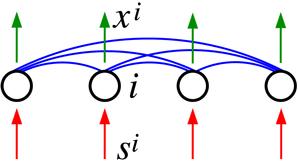
Figure 1. Lateral feedback interactions in a single layer of N neurons. The input signal si to a neuron i is converted to an output signal xi by a quick response dynamics ( |
We apply this predictive coding model to the MNIST dataset of hand-written digits. Our numerical results confirm the spontaneous breaking of synaptic weight symmetry, and they also demonstrate that a high input correlation between two neurons does not necessarily mean there will be strong direct interactions between them in the optimized network. Other properties of the lateral predictive coding are also demonstrated, including the reduction of correlation among the responses of different neurons, and the attention mechanism of highlighting novel spots in the input signals. Of special interest is the response speed of the optimized perception system to familiar input signals which are much faster than unfamiliar or random inputs. We believe that lateral recurrent interactions are indispensable in understanding predictive coding in biological nervous systems.
This paper is organized as follows. Section 2 describes the fast-time-scale response dynamics and introduces the synaptic matrix of lateral interactions. Section 3 defines the cost function to be minimized and derives the gradient descent iteration equations of the slow-time-scale adaptation of the synaptic weights. Section 4 reports the main numerical results obtained on the hand-written digits dataset. Finally, we conclude our work in section 5 .
2. Model
2.1. Response dynamics and internal state
We focus our attention on a single layer of neurons (figure 1). The N neurons in this layer are affected by external inputs, and they are also mutually affected by lateral interactions [2, 17–19]. We denote by si the external input to a neuron i, and by xi the internal state of this neuron. If there is no external perturbation, the neurons stay in the quiescent state (xi=0). Upon receiving an input signal ${\boldsymbol{s}}={\left({s}^{1},\ldots ,{s}^{N}\right)}^{\top }$ , the internal state vector ${\boldsymbol{x}}={\left({x}^{1},\ldots ,{x}^{N}\right)}^{\top }$ is driven away from quiescence and reaches a new steady state quickly, on a time scale of milliseconds. We assume the following simple response dynamics,
$\begin{eqnarray}\displaystyle \frac{{\rm{d}}{\boldsymbol{x}}}{{\rm{d}}t}={\boldsymbol{s}}-{\boldsymbol{x}}-{\boldsymbol{f}}({\boldsymbol{x}}).\end{eqnarray}$
The term − x on the right-hand side of this expression is spontaneous relaxation, whose time constant is defined as unity. The vector function ${\boldsymbol{f}}({\boldsymbol{x}})={\left({f}_{1}({\boldsymbol{x}}),\ldots ,{f}_{N}({\boldsymbol{x}})\right)}^{\top }$ contains all the lateral feedback interactions between the N neurons. These lateral interactions are generally nonlinear in a biological neural network. Here, for simplicity, we restrict the discussion to linear interactions and assume that the interaction function fi(x) has the following form1 ) has already incorporated the effect of possible self-loops.
$\begin{eqnarray}{f}_{i}({\boldsymbol{x}})=\sum _{j\ne i}{w}_{{ij}}{x}^{j},\end{eqnarray}$
where wij is the synaptic weight of the directed interaction from neuron j to neuron i. The synaptic weights define a lateral interaction matrix W as $\begin{eqnarray}{\boldsymbol{W}}=\left(\begin{array}{cccc}0 & {w}_{12} & \cdots & \ {w}_{1N}\\ {w}_{21} & 0 & \cdots & \ {w}_{2N}\\ \vdots & \vdots & \ddots & \vdots \\ {w}_{N1} & {w}_{N2} & \cdots & 0\end{array}\right).\end{eqnarray}$
Notice that all the diagonal elements are identical to zero, wii ≡ 0. Self-loops (autapses) actually exist in some types of neurons and they could induce rich dynamical phenomena [20]. In the present simplified model, we assume that the spontaneous relaxation term of equation (In response to an external signal s, the internal state of the linear recurrent dynamics (2 ) at time t is
$\begin{eqnarray}{\boldsymbol{x}}(t)=\left[{\boldsymbol{I}}-{{\rm{e}}}^{-({\boldsymbol{I}}+{\boldsymbol{W}})t}\right]{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}^{-1}{\boldsymbol{s}},\end{eqnarray}$
where I is the identity matrix (Iii = 1 for the diagonal elements, Iij = 0 for i ≠ j). The net driving force of this response at time t is simply dx/dt, and it is linearly depending on s, $\begin{eqnarray}\displaystyle \frac{{\rm{d}}{\boldsymbol{x}}}{{\rm{d}}t}={{\rm{e}}}^{-({\boldsymbol{I}}+{\boldsymbol{W}})t}{\boldsymbol{s}}.\end{eqnarray}$
Notice that, for x(t) to be convergent in this linear model, the real part of every eigenvalue of the composite matrix (I + W) needs to be positive. These eigenvalue conditions are checked in our numerical computations. (These constraints on the synaptic matrix may be unnecessary if the feedback functions are nonlinear and bounded, such as ${f}_{i}({\boldsymbol{x}})\,={a}_{0}\tanh \left({\sum }_{j\ne i}{w}_{{ij}}{x}^{j}\right)$ with a0 being a positive constant.)
2.2. Prediction and prediction error
This single layer of neurons is tasked with processing many input signal vectors sα, with index α = 1, 2,…, P. The total number P of input samples is much larger than the total number N of neurons. Each of these input vectors sα will be converted into an internal steady state ${{\boldsymbol{x}}}_{\alpha }={\left({x}_{\alpha }^{1},\ldots ,{x}_{\alpha }^{N}\right)}^{\top }$ by the recurrent dynamics (1 ), as
$\begin{eqnarray}{{\boldsymbol{x}}}_{\alpha }={\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}^{-1}{{\boldsymbol{s}}}_{\alpha }.\end{eqnarray}$
The internal representation xα is a linear transformation of sα. From this expression, we see that the input signal vector sα has been decomposed into two parts, $\begin{eqnarray}{{\boldsymbol{s}}}_{\alpha }={\boldsymbol{W}}{{\boldsymbol{x}}}_{\alpha }+{{\boldsymbol{x}}}_{\alpha }={{\boldsymbol{p}}}_{\alpha }+{{\boldsymbol{x}}}_{\alpha }.\end{eqnarray}$
The ith element of the first vector pα ≡ Wxα is ${p}_{\alpha }^{i}={\sum }_{j\ne i}{w}_{{ij}}{x}_{\alpha }^{j}$ and it is independent of ${x}_{\alpha }^{i}$ . We can therefore interpret ${p}_{\alpha }^{i}$ as the prediction by the other neurons concerning the input signal ${s}_{\alpha }^{i}$ of neuron i. Each neuron j contributes a term ${w}_{{ij}}{x}_{\alpha }^{j}$ to the predicted input signal at neuron i, and the column vector ${\left({w}_{1,j},\ldots ,{w}_{j-1,j},0,{w}_{j+1,j},\ldots ,{w}_{N,j}\right)}^{\top }$ characterizes the predictive role of neuron j. We refer to pα as the prediction vector. Then, equation (7 ) indicates that the internal state ${x}_{\alpha }^{i}$ of neuron i is also serving as a prediction error. When xα is received as input by another layer of neurons, it contains the residual properties of the signal vector sα that has not yet been predicted by the single-layer internal model W. In other words, ${x}_{\alpha }^{i}$ is both an internal state of neuron i itself and a prediction error for ${s}_{\alpha }^{i}$ . This dual role might be of real biological significance, as it relieves the necessity of introducing extra neurons for the sole purpose of computing prediction error [11]. In the literature, special error-computing neurons are commonly employed in hierarchical predictive coding network models [3]. Such neurons may not be strictly necessary (and indeed the biological evidence in support of their existence is weak). Top-down predictive messages can be directly fed into the single-layer response dynamics. The simplest way is to add a term − h(t) into the right-hand side of equation (1 ), with h(t) being the higher-level prediction concerning the input s.
The decomposition (7 ) will cause an interesting phenomenon of perceptive illusion. We explain this by a simple example, the gray image shown in figure 2. The eight small white squares surrounding the left central small square have gray intensity 0.0, the eight small black squares surrounding the right central small square have gray intensity 1.0, and the two central small squares have identical gray intensity 0.6. Let us set the weight wij from a square j to all its nearest surrounding squares i to be wij = 0.05 and set all the other weights to be zero. Then according to equation (6 ), the output gray value of the left small square will be 0.624 and that of the right small square is 0.254. The linear predictive coding model ‘perceives' the left central square to be much more darker than the right central square, even though their actual gray intensity is the same. This is an unconscious predictive perception, and this outcome is consistent with the conscious visual perception of humans. Unconscious predictive coding may be contributing to conscious optical illusions. We notice that recent computational investigations suggested that more complex visual illusions, such as the famous Kanizsa contours [21], could be quantitatively explained by hierarchical predictive coding models with feedback interactions [14].

Figure 2. An example of perceptive illusion. The gray intensities of the 18 small square blocks are 0.6 for the two central squares; 0.0 (white) for the eight squares surrounding the left central square; 1.0 (black) for the eight squares surrounding the right central square. The synaptic weights from a square j to all its surrounding squares i are set to wij = 0.05 and all the other synaptic weights are set to be zero. The perceived gray intensities of the left and right central squares are 0.624 and 0.254, respectively. |
3. Prediction error minimization
3.1. Mean squared prediction error
For the linear predictive coding model with P input signal vectors sα, we define the mean squared prediction error ϵ as${x}_{\alpha }^{i}$ is also the internal state of neuron i, the mean squared prediction error can also be understood as the mean metabolic energy needed to represent an external input. The synaptic weights wij of lateral interactions are modifiable on time scales much longer than that of the response dynamics (1 ). It is natural for us to assume that these synaptic weights will slowly adapt to the inputs to minimize the mean squared prediction error ϵ.
$\begin{eqnarray}\varepsilon =\displaystyle \frac{1}{2P}\sum _{\alpha =1}^{P}{\left({{\boldsymbol{x}}}_{\alpha }\right)}^{2}=\displaystyle \frac{1}{2P}\sum _{\alpha =1}^{P}\sum _{i=1}^{N}{\left({x}_{\alpha }^{i}\right)}^{2},\end{eqnarray}$
where xα is the prediction error vector corresponding to input sα. As Here we are interested in the properties of the optimized synaptic weights. To better appreciate the essence of this optimization task, we now rewrite the expression of ϵ in an alternative form. The empirical correlation matrix A for the N neurons is defined as ${\boldsymbol{A}}\equiv (1/P){\sum }_{\alpha =1}^{P}{{\boldsymbol{s}}}_{\alpha }{{\boldsymbol{s}}}_{\alpha }^{\top }$ , with elements${{\boldsymbol{u}}}_{m}\,\equiv {\left({u}_{1m},{u}_{2m},\ldots ,{u}_{{Nm}}\right)}^{\top }$ , which satisfy the orthonormal property ${{\boldsymbol{u}}}_{m}^{\top }{{\boldsymbol{u}}}_{m}=1$ and ${{\boldsymbol{u}}}_{m}^{\top }{{\boldsymbol{u}}}_{n}=0$ for m ≠ n. Any input signal vector sα could be uniquely expanded as${c}_{\alpha }^{m}$ is the coordinate along the mth eigenvector, namely ${c}_{\alpha }^{m}={{\boldsymbol{u}}}_{m}^{\top }{{\boldsymbol{s}}}_{\alpha }$ . The moments of these coordinates have the following important properties:${{\boldsymbol{z}}}_{m}={\left({z}_{1m},\ldots ,{z}_{{Nm}}\right)}^{\top }$ the internal representation of the eigenvector um,10 ), we know that its internal representation is10 ), but notice that the basis vectors zm are not necessarily orthogonal to each other and also that the squared norm $\parallel {\boldsymbol{z}}{\parallel }^{2}\equiv {{\boldsymbol{z}}}_{m}^{\top }{{\boldsymbol{z}}}_{m}\ne 1$ . The coordinates ${c}_{\alpha }^{m}$ are fixed by the input dataset, and the optimization targets are then the N internal vectors zm. The mean squared prediction error (8 ) is16 ) we have used the properties (11 ) and (12 ). The summation in equation (16 ) does not contain inner product terms ${{\boldsymbol{z}}}_{m}^{\top }{{\boldsymbol{z}}}_{n}$ with m ≠ n. This fact means that the orthogonality of the internal vectors zm is not a necessary condition for the minimization of ϵ.
$\begin{eqnarray}{A}_{{ij}}=\displaystyle \frac{1}{P}\sum _{\alpha =1}^{P}{s}_{\alpha }^{i}{s}_{\alpha }^{j}.\end{eqnarray}$
This real symmetric matrix has N non-negative eigenvalues λm, ranked in descending order λ1 ≥ λ2 ≥ … ≥ λN. The corresponding eigenvectors are denoted as $\begin{eqnarray}{{\boldsymbol{s}}}_{\alpha }=\sum _{m=1}^{N}{c}_{\alpha }^{m}{{\boldsymbol{u}}}_{m},\end{eqnarray}$
where $\begin{eqnarray}\left\langle {\left({c}_{\alpha }^{m}\right)}^{2}\right\rangle \equiv \displaystyle \frac{1}{P}\sum _{\alpha }{\left({c}_{\alpha }^{m}\right)}^{2}={\lambda }_{m},\end{eqnarray}$
$\begin{eqnarray}\left\langle {c}_{\alpha }^{m}{c}_{\alpha }^{n}\right\rangle \equiv \displaystyle \frac{1}{N}\sum _{\alpha }{c}_{\alpha }^{m}{c}_{\alpha }^{n}=0,\quad \quad (m\ne n).\end{eqnarray}$
Let us denote by $\begin{eqnarray}{{\boldsymbol{z}}}_{m}={\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}^{-1}{{\boldsymbol{u}}}_{m}.\end{eqnarray}$
In matrix form, this means $\begin{eqnarray}\begin{array}{l}\left(\begin{array}{cccc}1&{w}_{12}&\cdots &{w}_{1N}\\ {w}_{21}&1&\cdots &{w}_{2N}\\ \vdots &\vdots &\ddots &\vdots \\ {w}_{N1}&{w}_{N2}&\cdots &1\end{array}\right)\left(\begin{array}{cccc}{z}_{11}&{z}_{12}&\cdots &{z}_{1N}\\ {z}_{21}&{z}_{22}&\cdots &{z}_{2N}\\ \vdots &\vdots &\ddots &\vdots \\ {z}_{N1}&{z}_{N2}&\cdots &{z}_{{NN}}\end{array}\right)\\ \quad =\left(\begin{array}{cccc}{u}_{11}&{u}_{12}&\cdots &{u}_{1N}\\ {u}_{21}&{u}_{22}&\cdots &{u}_{2N}\\ \vdots &\vdots &\ddots &\vdots \\ {u}_{N1}&{u}_{N2}&\cdots &{u}_{{NN}}\end{array}\right).\end{array}\end{eqnarray}$
For any input signal vector sα, because of equation ( $\begin{eqnarray}{{\boldsymbol{x}}}_{\alpha }\equiv {\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}^{-1}{{\boldsymbol{s}}}_{\alpha }=\sum _{m=1}^{N}{c}_{\alpha }^{m}{{\boldsymbol{z}}}_{m}.\end{eqnarray}$
This expression has the same form as equation ( $\begin{eqnarray}\displaystyle \begin{array}{rcl}\varepsilon &=&\displaystyle \frac{1}{2P}\sum _{\alpha =1}^{P}\sum _{m=1}^{N}\sum _{n=1}^{N}{c}_{\alpha }^{m}{c}_{\alpha }^{n}{{\boldsymbol{z}}}_{m}^{\top }{{\boldsymbol{z}}}_{n}\\ &=&\displaystyle \frac{1}{2}\sum _{m=1}^{N}{\lambda }_{m}{\left({{\boldsymbol{z}}}_{m}\right)}^{2}\end{array}\end{eqnarray}$
$\begin{eqnarray}=\displaystyle \frac{1}{2}\sum _{m=1}^{N}{\lambda }_{m}{\left[{({\boldsymbol{I}}+{\boldsymbol{W}})}^{-1}{{\boldsymbol{u}}}_{m}\right]}^{2}.\,\end{eqnarray}$
In deriving equation (The two equivalent expressions (16 ) and (17 ) reveal that the mean squared prediction error does not depend on the details of the P input signal vectors but only on the eigenvalues and eigenvectors of the correlation matrix A. For the leading (largest) eigenvalues λm (m = 1, 2, …), it is desirable to reduce the squared norm of the corresponding internal vectors zm. On the other hand, there is no such necessity to optimize an internal vector zn if the eigenvalue λn is close to zero. The first eigenvector u1 and eigenvalue λ1 may be strongly related to the mean vector (1/P)∑αsα of the input signals. The remaining eigenvectors and eigenvalues are mainly related to the co-variance of the input signal vectors. We expect that the leading terms ${\lambda }_{m}{\left({{\boldsymbol{z}}}_{m}\right)}^{2}$ of equation (16 ) with m ≥ 2 will be roughly equal, i.e., $\parallel {{\boldsymbol{z}}}_{m}\parallel \sim {\lambda }_{m}^{-1/2}$ for m = 2, 3, … as a result of optimization. Because ${c}_{\alpha }^{m}\sim {\lambda }_{m}^{1/2}$ according to equation (11 ), the projections of the internal state xα in the different directions ${\hat{{\boldsymbol{z}}}}_{m}\equiv {{\boldsymbol{z}}}_{m}/\parallel {{\boldsymbol{z}}}_{m}\parallel $ of m = 2, 3, … will be comparable in magnitude. Suppose only a few numbers (say M ≈ 100) of λm values are important. Then, according to equation (15 ), the internal representation xα will be${\tilde{c}}_{\alpha }^{m}\equiv {c}_{\alpha }^{m}\parallel {{\boldsymbol{z}}}_{m}\parallel $ . The magnitudes of the coefficients ${\tilde{c}}_{\alpha }^{m}$ for 2 ≤ m ≤ M will be roughly equal if the scaling property ${\lambda }_{m}^{1/2}\parallel {{\boldsymbol{z}}}_{m}\parallel \sim 1$ is valid. The N internal direction vectors ${\hat{{\boldsymbol{z}}}}_{m}$ may not be strictly orthogonal to each other, but instead the angles between them may slightly deviate from π/2.
$\begin{eqnarray}{{\boldsymbol{x}}}_{\alpha }\approx {\tilde{c}}_{\alpha }^{1}{\hat{{\boldsymbol{z}}}}_{1}+\sum _{m=2}^{M}{\tilde{c}}_{\alpha }^{m}{\hat{{\boldsymbol{z}}}}_{m},\end{eqnarray}$
where 3.2. Evolution of synaptic weights
We minimize the mean squared prediction error (17 ) by the method of gradient descent, under the constraint that the real parts of all the eigenvalues of (I + W) are positive. In addition, considering that maintaining a nonzero synaptic weight has a metabolic cost, we introduce a quadratic energy term to each synaptic weight. The total cost function of the minimization problem is then
$\begin{eqnarray}C({\boldsymbol{W}})=\displaystyle \frac{1}{2}\sum _{m=1}^{N}{\lambda }_{m}{\left[{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}^{-1}{{\boldsymbol{u}}}_{m}\right]}^{2}+\displaystyle \frac{\eta }{2N}\sum _{i,j}{\left({w}_{{ij}}\right)}^{2},\end{eqnarray}$
where η is an adjustable penalty parameter (the scaling factor N−1 ensures that the two summation terms in the above expression are of the same order, that is, proportional to N).The first derivative of this cost function with respect to synaptic weight wij is
$\begin{eqnarray}\displaystyle \begin{array}{rcl}\displaystyle \frac{\partial C}{\partial {w}_{{ij}}}&=&-\sum _{m,n,p}{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}_{{jm}}^{-1}{A}_{{mn}}{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}_{{pn}}^{-1}{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}_{{pi}}^{-1}\\ &&\quad +\displaystyle \frac{\eta }{N}{w}_{{ij}}.\end{array}\end{eqnarray}$
In deriving this expression, we have used the following two relations $\begin{eqnarray}\displaystyle \begin{array}{rcl}{\left(\displaystyle \frac{\partial {\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}^{-1}}{\partial {w}_{{ij}}}\right)}_{{mn}}&=&-{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}_{{jn}}^{-1}{\left({\boldsymbol{I}}+{\boldsymbol{W}}\right)}_{{mi}}^{-1},\end{array}\end{eqnarray}$
$\begin{eqnarray}\displaystyle \begin{array}{rcl}{A}_{{mn}}&=&\sum _{k}{\lambda }_{k}{u}_{{mk}}{u}_{{nk}}.\end{array}\end{eqnarray}$
To minimize the total cost C by gradient descent, we modify all the synaptic weights wij (i ≠ j) simultaneously according to $\begin{eqnarray}{w}_{{ij}}\ \leftarrow \ {w}_{{ij}}-\gamma \displaystyle \frac{\partial C}{\partial {w}_{{ij}}},\end{eqnarray}$
where γ is a small learning rate.From the expression (20 ) of cost gradients, we observe that23 ) and starting from wij = wji = 0 will lead to breaking of symmetry between these two synaptic weights, that is, wij ≠ wji. We have checked by exact computation that this spontaneous symmetry-breaking phenomenon occurs even if there are only two neurons, N = 2.
$\begin{eqnarray}\displaystyle \frac{\partial C}{\partial {w}_{{ij}}}\ne \displaystyle \frac{\partial C}{\partial {w}_{{ji}}},\end{eqnarray}$
although the correlation matrix A is symmetric. Then the adaptation of wij and wji following (4. Numerical results
We apply the lateral predictive coding model to a widely used real-world dataset, the MNIST dataset of hand-written digits [22], with the purpose of gaining some empirical insights into the effects of lateral recurrent interactions. There are P = 60000 gray images of 28 × 28 pixels for the ten digits, each of which serves as an input vector (sα). We attach a neuron to each of the N = 784 pixels, and neurons and pixels will be mentioned interchangably in this section. The original pixel values are integers ranging from 0 to 255. Here we linearly re-scale these values to the range [0, 1]. The mean input vector, denoted as $\overline{{\boldsymbol{s}}}\equiv {\sum }_{\alpha =1}^{P}{{\boldsymbol{s}}}_{\alpha }/P$ , is a positive vector. The mean prediction vector and the mean prediction error vector are denoted by $\overline{{\boldsymbol{p}}}$ and $\overline{{\boldsymbol{x}}}$ , respectively. Naturally, these three mean vectors satisfy the relation $\overline{{\boldsymbol{s}}}=\overline{{\boldsymbol{p}}}+\overline{{\boldsymbol{x}}}$ .
For the convenience of later discussions, we define the (cosine) similarity q(v, y) of two generic m-dimensional vectors ${\boldsymbol{v}}={\left({v}_{1},\ldots ,{v}_{m}\right)}^{\top }$ and ${\boldsymbol{y}}={\left({y}_{1},\ldots ,{y}_{m}\right)}^{\top }$ as
$\begin{eqnarray}q({\boldsymbol{v}},{\boldsymbol{y}})\equiv \displaystyle \frac{{{\boldsymbol{v}}}^{\top }{\boldsymbol{y}}}{\parallel {\boldsymbol{v}}\parallel \ \parallel {\boldsymbol{y}}\parallel }=\displaystyle \frac{\sum _{k}{v}_{k}{y}_{k}}{{\left[\sum _{i}{v}_{i}^{2}\right]}^{\tfrac{1}{2}}{\left[\sum _{j}{y}_{j}^{2}\right]}^{\tfrac{1}{2}}}.\end{eqnarray}$
This similarity index measures the angle between v and y. For example, if v and y point in the same direction, then q(v, y) = 1; if they are orthogonal to each other, then q(v, y) = 0.4.1. Learning procedure
The linear predictive coding model requires all the eigenvalues of the composite matrix (I + W) to have a positive real part, so we numerically check all the eigenvalues of this matrix every T iteration steps (epochs) during the evolution process of equation (23 ). The inspection interval is initially set to be T = 1000. After the eigenvalue constraints are checked to be violated for the first time, the value of T is reduced to T = 100 and then fixed to this value. Each time the matrix (I + W) is checked to have at least one eigenvalue with a negative real part, the learning rate is reduced by half (γ ← γ/2), and the synaptic matrix W is also properly reset to carry out the next T evolution epochs. One biologically plausible way of resetting the synaptic weight matrix is by homeostatic scaling-down of all its elements by the same ratio [23]. Another simple way is to simply reset the weight matrix to the matrix W that was attained and recorded T epochs earlier. The numerical results reported in this section were obtained by the second resetting method, but we have checked that the final numerical values of the synaptic weights are not sensitive to the particular method used to guarantee the eigenvalue condition, nor to whether the iteration (23 ) was performed synchronously or in random sequential order. The learning rate is initially set to be γ = 0.001. We train the network using PyTorch (version 1.10.0) and Python (version 3.9.7), which are quite convenient for matrix manipulations.
We consider three representative values for the penalty parameter: strong penalty, η = 50; moderate penalty, η = 10; weak penalty, η = 1. For η = 50 we find that all the eigenvalues of (I + W) never violate the positivity condition during the whole evolution process, while weight matrix resettings are needed at η = 10 and η = 1. We find that the properties of the systems obtained at different values of η are actually very similar qualitatively.
Figure 3(a) shows the decay curves of the mean squared prediction error ϵ with the learning epoch. At a large weight penalty (η = 50) the value of ϵ decreases to a final value which is about 0.23 of the initial value in about 104 epochs. At moderate or low weight penalty (η = 10 or η = 1) it takes longer for ϵ to saturate, but the final value is considerably lower ( ≈ 0.16 of the initial value). Resetting or rescaling of the weight matrix is needed at η = 10 or η = 1. The first 500 or so eigenvalues of the correlation matrix A (equation (9 )) of the input vectors sα and the corresponding eigenvalues of the correlation matrix of the internal states xα are shown in figure 3(b) for comparison. The first eigenvalue λ1 of the correlation matrix is much larger than the second eigenvalue λ2. This is mainly caused by the fact that the mean input vector $\overline{{\boldsymbol{s}}}$ is a relatively large positive vector. We see that, as a consequence of the decomposition (7 ), the first 100 eigenvalues of the internal states are considerably reduced as compared with those of the input data. The relationship $\parallel {{\boldsymbol{z}}}_{m}\parallel \sim {\lambda }_{m}^{-1/2}$ is confirmed to be roughly true for m ≥ 2 (figure 3(c)).
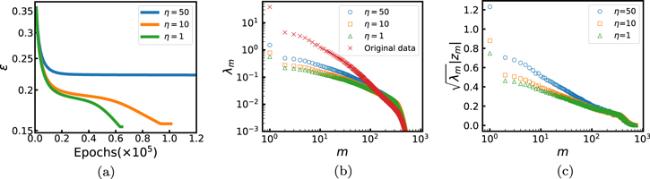
Figure 3. (a) Evolution of the mean squared prediction error ϵ (relative to the initial value before weight adaptation). (b) The eigenvalues λm of the correlation matrix of the input data samples sα and of the correlation matrix of the internal states xα. (c) The values of |
The distribution of similarity q(sα, sβ) between two input images of the MNIST dataset, and the corresponding distributions of similarity q(pα, pβ) and q(xα, xβ) are compared in figure 4(a). The distribution of q(xα, xβ) is sharply peaked around zero, suggesting that the prediction error vectors xα of the 60 000 data samples are approximately orthogonal to each other. This is a clear demonstration of redundancy reduction in xα. In comparison, we find that both q(sα, sβ) and q(pα, pβ) peaked at relatively large positive values, which may be mainly due to the fact that the mean input vector $$\overline{{\boldsymbol{s}}}$ and the mean prediction vector $\overline{{\boldsymbol{p}}}$ are both nonzero. If we subtract the mean vectors to get the mean-corrected vectors (${\rm{\Delta }}{{\boldsymbol{s}}}_{\alpha }={{\boldsymbol{s}}}_{\alpha }-\overline{{\boldsymbol{s}}}$ , ${\rm{\Delta }}{{\boldsymbol{p}}}_{\alpha }={{\boldsymbol{p}}}_{\alpha }-\overline{{\boldsymbol{p}}}$ , and ${\rm{\Delta }}{{\boldsymbol{x}}}_{\alpha }={{\boldsymbol{x}}}_{\alpha }-\overline{{\boldsymbol{x}}}$ ), the similarity distributions of Δsα and Δpα both are shifted to be peaked close to zero and also their standard deviations become slightly broader (figure 4(b)). On the other hand, this mean-correction treatment does not have a significant effect on the prediction error, probably because the mean vector $\overline{{\boldsymbol{x}}}$ are already quite small (the mean value of its N elements is about 0.01 at η = 1).

Figure 4. Histogram of similarity values between 60 000 vectors. Solid curves: input signal vectors sα (a) and the mean-corrected ones |
4.2. Nonsymmetry and sparsity of synaptic weights
The gradient descent dynamics start from the all-zero synaptic weight matrix W (wij = wji = 0 for all the pair-wise interactions). Our simulation results confirm the theoretical expectation of section 3.2 that the symmetry property of W breaks down as a result of optimisation (figure 5), and wij ≠ wji. This nonsymmetry could be quite large for some of the neuron pairs. As an example, consider a neuron i located at the central pixel (14, 14) in figure 6 and a neighboring neuron j located at pixel (15, 14). These two neurons are highly correlated in MNIST, with Aij = 0.304. At η = 1 we find that wij = 0.145 while wji = 0.570, which means that the state of neuron i has a strong direct effect on that of neuron j but the opposite is not true.

Figure 5. Symmetry breaking of the synaptic weight matrix W. Here wij is the synaptic weight from neuron j to neuron i. The penalty parameter is η = 50 (a), η = 10 (b), and η = 1 (c). |
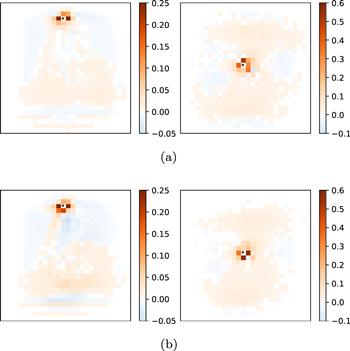
Figure 6. Receptive fields wij and projection fields wji for two neurons i, whose positions at (4, 14) and (14, 14) are marked by the ‘*' symbols. The weight penalty parameter is η = 1. (a) The input synaptic weights wij to the focal neuron i from all the other neurons j. (b) The output synaptic weights wji from the focal neuron i to all the other neurons j. |
We quantify the average degree of nonsymmetry by the following ratio κ
$\begin{eqnarray}\kappa =\displaystyle \frac{1}{N(N-1)}\sum _{i\ne j}\displaystyle \frac{| {w}_{{ij}}-{w}_{{ji}}| }{\left(| {w}_{{ij}}| +| {w}_{{ji}}| \right)}.\end{eqnarray}$
At a strong synaptic penalty (η = 50) the nonsymmetry ratio is relatively small (κ = 0.278); as the synaptic penalty is lowered to η = 10, the nonsymmetry ratio increases to a relatively large value of κ = 0.514; further decreasing the penalty to η = 1 only has a tiny effect on the nonsymmetry ratio (κ = 0.476). As the penalty value η decreases, the synaptic weights have more flexibility to take larger values. Figures 5(b) and (c) clearly demonstrate that, if the synaptic weight wij from neuron j to neuron i is large enough (wij > 0.3), the reverse synaptic weight wji from i to j is highly likely to be much smaller, with the sum wij + wji being roughly a constant value.We define the lateral receptive field of a neuron i as the subset of other neurons j with their synaptic weights wij to neuron i significantly deviating from zero. For the two-dimensional MNIST system, we find that the receptive field of each neuron i is considerably localized and is sparse: only a few of the input synaptic weights wij are distinctively large and the afferent neurons j are spatial neighbors (figure 6(a)). Both the sparsity property and the locality property may be a consequence of the fact that the correlations in the MNIST system are mostly contributed by spatially neighboring pixels. For the MNIST dataset, all the elements Aij of the correlation matrix are non-negative, and non-surprisingly, all the large-magnitude synaptic weights wij are positive.
Similarly, the lateral projection field of a neuron i is defined as the subset of other neurons j to which the synaptic weights wji are significantly distinct from zero. Same as the receptive fields, the projection field of a neuron is also sparse and spatially localized (figure 6(b)). Because of the nonsymmetric property, however, the projection field of a neuron i are not identical to its receptive field. For example, the central pixel i at (14, 14) is mostly affected by the pixel j at (13, 14) and the synaptic weight is wij = 0.520, but pixel i affects mostly the two neurons k at (15, 14) and l at (14, 15), with synaptic weights wki = 0.570 and wli = 0.571. Figure 6 also indicates that at the central pixel i there is a strong directional flow of influence from the north side to the eastern and southern sides. Qualitatively similar directional motifs might be common in the biological brain.
For some of the neurons located close to the boundary of the square region, we find that their receptive and projection fields are both empty. In other words, the synaptic weights from other neurons j and to other neurons are both vanishing (wij ≈ 0 and wji ≈ 0). These neurons are therefore isolated from the other neurons. We find that this isolation is due to the fact that such a neuron i is almost always quiescent (si=0).
In a natural environment, the visual signals to the retina of an animal are strongly redundant and locally correlated. The locality of the synaptic weights in visual signal processing systems has been well documented [2, 8]. Quantitative experimental investigations on the degree of nonsymmetry κ in these lateral interactions may be an interesting experimental issue. It may also be possible that different regions of the cerebral cortex will have different values of the nonsymmetry index κ.
4.3. Neuron pair-wise similarity
For two P-dimensional vector ${{\boldsymbol{s}}}^{i}={\left({s}_{1}^{1},\ldots ,{s}_{P}^{1}\right)}^{\top }$ and ${{\boldsymbol{s}}}^{j}\,=({s}_{1}^{2},\ldots ,{s}_{P}^{2})$ , one on neuron i and the other on neuron j, the similarity q(si, sj) between them is computed as
$\begin{eqnarray}q({{\boldsymbol{s}}}^{i},{{\boldsymbol{s}}}^{j})\equiv \sum _{\alpha =1}^{P}\displaystyle \frac{{s}_{\alpha }^{i}{s}_{\alpha }^{j}}{\parallel {{\boldsymbol{s}}}^{i}\parallel \ \parallel {{\boldsymbol{s}}}^{j}\parallel }.\end{eqnarray}$
This similarity is related to the input correlation Aij by $\begin{eqnarray}q({{\boldsymbol{s}}}^{i},{{\boldsymbol{s}}}^{j})=\displaystyle \frac{P}{\parallel {{\boldsymbol{s}}}^{i}\parallel \ \parallel {{\boldsymbol{s}}}^{j}\parallel }{A}_{{ij}}.\end{eqnarray}$
In other words, q(si, sj) is a re-scaled correlation of the input signals at neurons i and j.The top row of figure 7 shows the relationship between the input similarity q(si, sj) of two neurons i and j and the synaptic weights wij and wji. There is a clear trend of wij increasing with q(si, sj), which is naturally anticipated. A large value of synaptic weight wij implies a large value of similarity q(si, sj). Very interestingly, however, the reverse is not necessarily true. The synaptic weight wij or wji (or both) could be very close to zero even if the similarity q(si, sj) is quite large. For example, the input similarity of pixel i at (23, 14) and pixel j at (26, 11) is q(si, sj) = 0.238 while both wij and wji are very small ( ≈ 2 × 10−5). This means that the lateral neural network may choose to predict the input signal of a neuron i based on the internal states of a few (but not all) of the most highly correlated neurons j. The underlying reason might be the redundancy of information in the input signals. If the input signals of both neurons j and k are good predictors of that of neuron i, one of the synaptic weights wij and wik may be spared to reduce synaptic energy.

Figure 7. Synaptic weights, input correlations and internal correlations. (a–c, top row) Relationship between synaptic wij and q(si, sj) (the similarity of input signals at neurons i and j). (d–f, bottom row) The relationship between q(xi, xj) (the similarity of internal representations at i and j) and input similarity q(si, sj). The dotted lines mark the hypothetical linear relation q(xi, xj) = q(si, sj). In drawing this figure, we only include neurons whose input signals are sufficiently active, that is, the input signals |
In some sense, the lateral neural network attempts to explain the complicated correlations of the input signal vectors by a few ‘direct' interactions. This is similar to recent work on direct coupling analysis in neural sequences and protein sequences, which also tried to distinguish between direct interactions and indirect transmission of correlations [24, 25].
The internal states ${x}_{\alpha }^{i}$ of a neuron i depend on the input pattern and they also form a P-dimensional vector ${{\boldsymbol{x}}}^{i}\,={\left({x}_{1}^{i},\ldots ,{x}_{P}^{i}\right)}^{\top }$ . The similarity q(xi, xj) between the internal vectors of two neurons is
$\begin{eqnarray}q({{\boldsymbol{x}}}^{i},{{\boldsymbol{x}}}^{j})\equiv \sum _{\alpha =1}^{P}\displaystyle \frac{{x}_{\alpha }^{i}{x}_{\alpha }^{j}}{\parallel {{\boldsymbol{x}}}^{i}\parallel \ \parallel {{\boldsymbol{x}}}^{j}\parallel }.\end{eqnarray}$
As demonstrated in the bottom row of figure 7, the internal similarity between two neurons i and j is much smaller than the input similarity between them, that is, $\begin{eqnarray}q({{\boldsymbol{x}}}^{i},{{\boldsymbol{x}}}^{j})\ \lt \ q({{\boldsymbol{s}}}^{i},{{\boldsymbol{s}}}^{j}).\end{eqnarray}$
To be more quantitative, the mean value of q(si, sj) averaged over all the neuron pairs is 0.176, while the mean value of ∣q(xi, xj)∣ is only 0.023 at η = 1. Clearly, as a consequence of predictive learning, the correlations among the internal states of different neurons are much reduced in comparison with the strong input correlations. This is a known advantage of predictive coding [3].There are still considerable correlations between the internal states of many neurons and the internal similarities q(xi, xj) between these neurons are quite distinct from zero. An interesting idea might be to take the internal state vectors xα as input training signals to another laterally connected layer of predictive coding neurons. This hierarchical sequence may need to be extended to more layers, until the output vectors are formed by mutually independent elements. In this way, hierarchical predictive coding becomes a renormalization model [26–28]. There may be only a few elements of the final output vector that are significantly different from being zero, and they may offer an obvious classification of the initial input digital pictures. This idea needs to be explored in the future.
4.4. Surprisal, attention, and prediction
We present in the top row of figure 8 the result of the response dynamics obtained for a randomly chosen image sample sα (a digit 5). The prediction error (xα) and prediction (pα ≡ Wxα) vectors of this example share some common features with the results obtained on the other samples of the MNIST dataset. First, we find that the predictions pα are visually quite similar with the input signal sα. For instance, at weight penalty η = 1 the similarity between these two N-dimensional vectors,
$\begin{eqnarray}q({{\boldsymbol{s}}}_{\alpha },{{\boldsymbol{p}}}_{\alpha })\equiv \displaystyle \frac{1}{\parallel {{\boldsymbol{s}}}_{\alpha }\parallel \ \parallel {{\boldsymbol{p}}}_{\alpha }\parallel }\sum _{i=1}^{N}{s}_{\alpha }^{i}{p}_{\alpha }^{i},\end{eqnarray}$
has a high value of 0.93± 0.03, averaged over all the 60 000 digital samples. The optimized synaptic weight matrix W could explain the input correlations with high precision.
Figure 8. Examples of input signal vectors sα (left column), the predicted signals pα = Wxα (middle column), and the prediction errors xα (right column). The top left sample is an intact symbol ‘5', while the bottom left sample is an occluded version with some pixels of high intensities being changed to zero intensity (white). The occluded pixels are indicated by a small ‘⋆' in the bottom row. The network is trained with weight penalty η = 1. |
Second, we observe that the magnitude $| {x}_{\alpha }^{i}| $ of the prediction error is often most significant at the boundary pixels of the original digit symbols, and the spatial gradients of ${x}_{\alpha }^{i}$ at this boundary pixels are comparatively large and the signs of ${x}_{\alpha }^{i}$ also change at these pixels i. In other words, the prediction error vector xα highlights the boundary separating the digital symbol and the background. The neurons correspond to the interior pixels of the symbol and to the regions far-away from the symbol often have a lower magnitude of internal responses. The prediction error ${{\boldsymbol{x}}}_{\alpha }^{i}$ is the level of surprise with which a neuron i feels about the input signal sα. A relative large magnitude of ${x}_{\alpha }^{i}$ may help the neural system to pay special attention to the pixel corresponding to neuron i. This is a simple attention mechanism of novelty detection, and in our present model it does not involve the transfer of top-down messages from the higher hierarchical neural layers.
Prediction and novelty detection are most clearly manifested for input digital signals sα of which some pixels are occluded (namely, the original nonzero input pixel values ${s}_{\alpha }^{i}$ are artificially set to be zero). We find that even with many pixels being occluded, the network could still offer a highly satisfying prediction (pα) for the original intact image (bottom row of figure 8). On the other hand, the prediction errors are the most significant for the occluded pixels, which could guide attention to these regions. These simulation results on occluded input signals demonstrate clearly the dual role of xα being both an internal model (by combining W) and a prediction error vector.
How will a biological brain possibly take advantage of decomposition (7 ) to facilitate perception and action? Maybe the prediction pα and the prediction error xα will be transmitted through different paths to different higher-level processing units. The possible biological significance of this needs to be explored more deeply. We notice that there are actually at least two pathways of the visual information process in the human brain [29]. One of these pathways (the dorsal visual pathway) is responsible for unconscious blindsight [30], and a ventral visual pathway is more closely related to conscious perception.
4.5. Response time variations
The predictive coding and perception system counteracts an input signal vector s by the combined effect of internal state x and prediction Wx. Figure 9(a) reveals the averaged decay behavior of the magnitude of the difference vector [s − (x + Wx)] with time. We define the response time τ(s) of the dynamics (1 ) to input signal s as the earliest time at which the magnitude of the difference vector becomes less than 1/e of the initial magnitude ∥s∥. According to equation (5 ), then τ(s) is determined by the equation
$\begin{eqnarray}\displaystyle \frac{\parallel {{\rm{e}}}^{-({\boldsymbol{I}}+{\boldsymbol{W}})\tau }{\boldsymbol{s}}\parallel }{\parallel {\boldsymbol{s}}\parallel }=\displaystyle \frac{1}{{\rm{e}}}.\end{eqnarray}$
If there are no feedback interactions, the response dynamics will be purely exponential and the response time would be the same for any input vector s, and τ(s) = 1. The response time is much reduced by the introduction of optimized feedback interactions. For the synaptic weight matrix attained with a high penalty (η = 50) the mean response time is τ = 0.41 ± 0.06 among all the MNIST image samples. This mean response time is further reduced to τ = 0.33 ± 0.06 at moderate penalty η = 10 and to τ = 0.31 ± 0.07 at low penalty η = 1.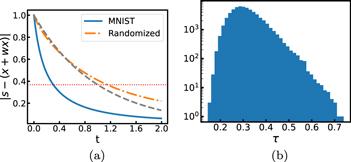
Figure 9. Response time of predictive coding. The weight matrix is trained at penalty value η = 1. (a) The average decay behavior of the magnitude of the difference vector [s − (x + Wx)] (rescaled by the magnitude of the input signal s) wth time t. The solid line is obtained for the MNIST images and the dot-dashed line is obtained for the shuffled MNIST images, while the dashed line is obtained for W = 0 (no interactions). The horizontal thin line marks the level 1/e. (b) The histogram of response times τ obtained for the MNIST images. |
For each MNIST image vector s we randomly exchange the positions of its elements (si ↔ sj for pairs of randomly chosen indices i and j) and feed the shuffled vector to the network. Very interestingly, we find the response time of the network to such a maximally randomized input is not reduced but rather is increased beyond unity (figure 9(a)). This indicates that the recurrent network has the ability to distinguish familiar inputs on which the weight matrix is trained from unfamiliar or novel inputs.
The response times for the original image vectors also differ considerably, ranging from τ = 0.15 to τ = 0.73 at η = 1 [figure 9(b)]. The ten images s with the shortest response times are shown in figure 10(a), all of which are found to have very high similarity with the averaged input $\overline{{\boldsymbol{s}}}$ , with values $q({{\boldsymbol{s}}}_{\alpha },\overline{{\boldsymbol{s}}})\gt 0.9$ . On the other hand, we find that the similarity of the averaged input $\overline{{\boldsymbol{s}}}$ with the leading eigenvector ${\hat{e}}_{1}$ of the synaptic weight matrix is very large, $q(\overline{{\boldsymbol{s}}},{\hat{{\boldsymbol{e}}}}_{1})=0.9992$ at η = 1. Then it is easy to understand why these images will be quickly responded by the predictive coding dynamics. The ten images with the longest response times are also shown in figure 10(b), which are all quite thin and are obviously distinct from the images in figure 10(a). We find these later images are only weakly aligned with ${\hat{{\boldsymbol{e}}}}_{1}$ and $\overline{{\boldsymbol{s}}}$ (the similarity value $q({{\boldsymbol{s}}}_{\alpha },\overline{{\boldsymbol{s}}})\approx 0.3$ ).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 10. Then ten MNIST images with the shortest response times (a), and the ten images with the longest response times (b). The weight matrix is optimized with a penalty value η = 1. |
The synaptic weights of our network are not trained explicitly to reduce response time. So this elevated response to familiar input signals should be regarded as an extra benefit of predictive perception. The ability to respond quickly to external stimuli is highly desirable in the animal world. The response time τ(s) could be used as a measure of the typicality of the input vector s. According to figure 10(b) the input samples with response time τ ≈ 0.25 − 0.4 may be regarded as typical inputs, while those with τ < 0.2 or τ > 0.6 may be considered untypical ones.
5. Concluding remarks
We studied lateral feedback interactions in a simple model of neural response dynamics (1 ) from the perspective of predictive coding. Lateral interactions between two neurons were implemented through the synaptic weights wij of the linear response function (2 ). An optimization problem was formulated to minimize prediction errors, and the method of gradient descent was adopted to evolve the synaptic weights towards near-optimal values. We applied our optimization algorithm to the MNIST dataset of hand-written digits. Our empirical results demonstrated the following four major properties of lateral predictive coding: first, the symmetry of interactions is broken in the synaptic weight matrix, with the degree of nonsymmetry κ being significantly positive (equation (25 )); second, the similarity between the internal states xi and xj of neurons i and j are significantly reduced as compared to the similarity of the input signals si and sj (equation (29 )); third, strong correlations between two neurons i and j do not necessarily mean large synaptic weights between these neurons; and fourth, the response time to familiar input signals is significantly shortened (figure 9).
These properties of predictive coding may be highly relevant for information processing in biological neural systems. A natural extension of the present model is a multilayered hierarchical neural network will lateral interactions at individual single layers and feedforward and feedback interactions between adjacent layers. The whole network of the present model could serve as a single layer for a multilayered hierarchical neural information processing system. We did not address the possible effects of lateral interactions in tasks such as data classification and memory retrieval, but these are interesting issues for continued investigations [13, 15, 31].
The linear feedback interactions (2 ) are surely too simplistic for biological neurons. The firing rate of a biological neuron is a highly nonlinear and bounded function of the input signals, and irrelevant information may be lost during the coding and relaying process. Some of the most widely adopted nonlinear functions for theoretical analysis are the logistic function fi(x) = 1/(1 + e−x) and the hyperbolic tangent function ${f}_{i}(x)=\tanh (x)$ [17, 18]. The introduction of nonlinearity may bring much-enhanced competition among the internal states of different neurons, and consequently, it may dramatically affect the learned synaptic weights and change the statistical properties of the internal presentations x. It may be helpful to start with the extremely nonlinear Heaviside threshold response fi(x) = Θ(x − θi), with θi being the activation threshold of neuron i, to explore the effects of nonlinear lateral interactions in predictive coding.
Another rewarding direction is to consider spiking neurons that are biologically more realistic [16]. The simple noise-free response dynamics (1 ) then will be replaced by the more complicated and stochastic integrate-and-fire dynamics of spiking neurons. Much future work is needed to understand the effect of lateral feedback interactions in predictive coding neural networks and the competition and cooperation between lateral and top-down feedback interactions.