



1. Introduction
Non-equilibrium dynamics is a central topic of statistical physics [1–3], from which general fluctuation-dissipation relations can be established [4–6], and a path integral approach was developed to derive the relationship between the correlation and response function of the dynamics [7–9]. One benchmark for testing or deriving theoretical hypotheses are the Langevin dynamics with conservative (expressed as the gradient of a potential) or nonconservative forces, including Ising spin glass dynamics [10], steady-state thermodynamics [11], and neural dynamics with partially symmetric couplings [12]. These studies always resort to dynamical mean-field theory (DMFT) [13, 14], where all possible trajectory paths are integrated to give a physical action, from which the correlation and response functions are derived as an optimization of the action [15]. In a general context, the dynamics would be very complicated, e.g., non-gradient and highly coupled, which makes the DMFT very complicated, and it remains unknown how to capture the steady-state properties of these dynamics.
It is commonly observed that the speed of the dynamics determines whether the system enters a steady-state and thus can be identified [16]. In this paper, we propose a new angle that only the low-speed or zero-speed region of the phase space is considered. In this sense, one can write down an energy cost function to optimize for satisfying this speed constraint. This optimization can be formulated under the stochastic gradient dynamics, where a temperature-like parameter is introduced. This temperature plays the same role as in the canonical Boltzmann measure. In fact, in the zero temperature and stationary limit, the gradient dynamics under this approximate (or quasi) potential are self-consistent with the original general dynamics. Therefore, if the ground state of the energy cost is concentrated, one can capture the steady-state properties of the original phase space. This has an additional benefit that powerful equilibrium concepts such as the Boltzmann measure, phase transitions, and order parameters can be leveraged [17].
We verify our framework in recurrent neural networks with asymmetric couplings, where the deterministic dynamics yield an order-to-chaos transition [18, 19]. We are able to handle the quenched disorder due to the coupling statistics with the help of the replica method, a powerful trick in the spin glass theory [20]. Furthermore, two types of order parameters are naturally derived; one describes the network activity, while the other describes the response property of the dynamic system. The former order parameter exhibits a continuous phase transition from a null to positive value as the network parameters are tuned, while the latter one shows a peak at the exact location of the transition, thereby offering rich physical information about the steady-state of the complicated non-gradient dynamics. Our framework also makes it possible to analytically study the quasi-potential landscape of general dynamics, using the large-deviation principle and landscape analysis in equilibrium statistical mechanics [17, 21], which is left for a forthcoming work [22].
2. Model
We consider a recurrent neural network (RNN) composed of N interacting neurons, whose architecture is shown in figure 1(a), illustrated as a simple example of N = 3. The network activity is described by N real-valued synaptic currents (x). In the following, we use the bold symbol to indicate a vector or a matrix. The connection strength Jij measures the asymmetric impact from neuron j to neuron i. Note that in our model, two neurons do not have to interact with each other equally, i.e. Jij ≠ Jji. In addition, Jii = 0. All neurons are fully connected. The synaptic currents are transferred to firing rates through the current-to-rate transfer function φ( · ). Each neuron integrates neighboring activity via the incoming asymmetric synapses, and therefore the dynamics of the current are expressed as the following first-order non-linear differential equation for all i [18, 23]
$\begin{eqnarray}\displaystyle \frac{{\rm{d}}{x}_{i}}{{\rm{d}}t}=-{x}_{i}+\displaystyle \sum _{j=1}^{N}{J}_{{ij}}\phi ({x}_{j}),\end{eqnarray}$
where we consider unit time scale. Unless otherwise stated, $\phi =\tanh $. In this case, the transferred neural activity may become negative, while for biological reality, the non-negative function form should be chosen. However, our following analysis is still applicable to this type of non-negative transfer function.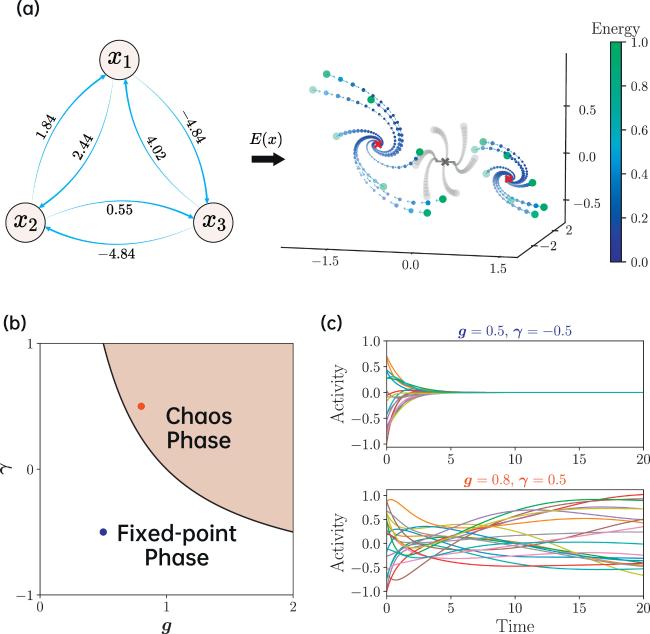
Figure 1. The key idea of our quasi-potential method and the phase diagram of the considered RNN model. (a) A three-neuron recurrent neural network is shown in the left panel. Neurons are bidirectionally connected with the strength displayed near the arrows (synaptic directions). Both connections in opposite directions are correlated once γ ≠ 0. Here, we simulate the RNN dynamics [equation ( |
In real neural circuits, Jij may not be identically independently distributed (i.i.d.). We therefore consider the correlated case whose statistics are specified below
$\begin{eqnarray}\left\langle {\left({J}_{{ij}}\right)}^{2}\right\rangle =\displaystyle \frac{{g}^{2}}{N},\end{eqnarray}$
$\begin{eqnarray}\left\langle {J}_{{ij}}{J}_{{ji}}\right\rangle \,=\,\displaystyle \frac{{g}^{2}}{N}\gamma ,\end{eqnarray}$
where g > 0 is called the gain parameter, which controls the variance of connections, and γ ∈ [ − 1, 1] controls the degree of connection symmetry. The special cases of γ = 1 and γ = − 1 correspond to symmetric and anti-symmetric neural networks, respectively, while γ = 0 corresponds to fully asymmetric networks [18].The above dynamics model exhibits an order-to-chaos transition [19]. The average (over the coupling realizations) number of equilibria explodes as the synaptic gain exceeds a critical value [24]. The critical gain value can be derived from the rightmost boundary of the asymptotic eigenvalue spectrum of J [25]. When g(1 + γ) < 1, the network stays in the trivial fixed-point phase, where all trajectories flow to the zero-activity stable state. Once g(1 + γ) > 1, the network activity enters a chaotic phase, where an infinitesimal separation of two trajectories would be eventually amplified, and individual neurons exhibit slow to fast time scales as the network parameters go deep into the chaotic phase. We illustrate the phase diagram in figure 1(b) and show the representative dynamic behaviors of these two phases in figure 1(c).
Intuitively, the phase space is partitioned into different regions of different speeds ($\parallel \displaystyle \frac{{\rm{d}}{\boldsymbol{x}}}{{\rm{d}}t}{\parallel }^{2}$). We are interested in the zero-speed or low-speed regions [16]. Focusing on the speed landscape, we design the following approximate potential (quasi-potential) of the dynamics,
$\begin{eqnarray}E({\boldsymbol{x}})=\displaystyle \frac{1}{2}\displaystyle \sum _{i}{\left(-{x}_{i}+\displaystyle \sum _{j=1}^{N}{J}_{{ij}}\phi ({x}_{j})\right)}^{2}+\eta \parallel {\boldsymbol{x}}{\parallel }^{2},\end{eqnarray}$
where the first term is the kinetic energy, the second term is a regularization term constraining the ℓ2 norm of the network activity. η plays the role of tuning the relative strength of the regularization to the kinetic energy. Here, we transform the studies of non-equilibrium steady states of non-gradient dynamics into an optimization of searching for the low-speed or zero-speed regions of the phase space, which corresponds to local or global minima of the above quasi-potential. This potential is equivalent to Hamiltonian in equilibrium statistical physics.According to equation (4 ), we can write down the following stochastic gradient dynamics (or Langevin dynamics)5 ) in the component-wise, i.e., $-\tfrac{\partial E({\boldsymbol{x}})}{\partial {x}_{i}}\equiv {F}_{i}$ where4 ) is not a Lyapunov function, and even the steady-state potential whose analytic form for the current out-of-equilibrium dynamics with asymmetric couplings is unknown [26], although the driving force is argued to be decomposed into the gradient of a potential (not the Lyapunov function as well) related to the steady-state distribution and a divergent-free curl flux [27]. It is still challenging to get the exact form of the potential for this decomposition. In contrast, we start from an optimization angle that concentrates on the low-speed region of the phase space and formulate the steady-state behavior as the canonical ensemble of stationary fixed points.
$\begin{eqnarray}\displaystyle \frac{{\rm{d}}{\boldsymbol{x}}}{{\rm{d}}t}=-{{\rm{\nabla }}}_{{\boldsymbol{x}}}E({\boldsymbol{x}})+\sqrt{2T}{\boldsymbol{\epsilon }},\end{eqnarray}$
where ε(t) is a time-dependent white noise, whose statistics are given by $\left\langle {\epsilon }_{i}(t)\right\rangle =0$, $\left\langle {\epsilon }_{i}(t){\epsilon }_{j}(t^{\prime} )\right\rangle ={\delta }_{{ij}}\delta (t-t^{\prime} )$. The temperature T is used to tune the energy level, playing the same role as in the equilibrium Boltzmann measure. We can write the gradient (force) in equation ( $\begin{eqnarray}{F}_{i}\equiv -{x}_{i}+{h}_{i}-\phi ^{\prime} ({x}_{i})\displaystyle \sum _{j:j\ne i}{J}_{{ji}}({h}_{j}-{x}_{j}),\end{eqnarray}$
where hi ≡ ∑j:j≠iJijφ(xj), and the last term explains the feedback effects due to neuron i whose activity yields impacts on its neighbors. From this expansion, we can see that only in the stationary limit (T → 0 as well), do the above Langevin dynamics yield the same state space as that of the original dynamics (e.g., stable or unstable fixed points). In this sense, the energy defined in equation (It is well-known that the steady-state of the above Langevin dynamics has an equilibrium Boltzmann measure [1],
$\begin{eqnarray}P({\boldsymbol{x}})=\displaystyle \frac{1}{Z}{{\rm{e}}}^{-\beta E({\boldsymbol{x}})},\end{eqnarray}$
where the partition function Z depends on particular realizations of J, and β = 1/T. An illustration of E(x) is given in figure 1(a). Our main focus is to compute the free energy of this canonical ensemble and derive the fixed-point properties of the dynamics model. The theoretical predictions can be confirmed by simulating the discretized Langevin dynamics, assuming the small discretization step as a learning rate, akin to a Monte Carlo simulation. We remark that this equilibrium analysis reproduces the continuous nature of the dynamics transition, more insights and the possibility of exploring the speed landscape will be discussed in the remaining sections.3. Replica method
To derive the quenched disorder average of the free energy, we apply the replica method, which is popular in studying the theory of spin glasses [20] and statistical mechanics of neural networks [17]. We first write down the following replicated partition function
$\begin{eqnarray}\begin{array}{rcl}{Z}^{n} & = & \displaystyle \int {\rm{d}}{\boldsymbol{x}}\exp \left[-\beta \left(\displaystyle \frac{1}{2}\displaystyle \sum _{{ia}}{\left(-{x}_{i}^{a}+\displaystyle \sum _{j}{J}_{{ij}}\phi ({x}_{j}^{a})\right)}^{2}\right.\right.\\ & & \left.\left.+\eta \displaystyle \sum _{a}| | {{\boldsymbol{x}}}^{a}| {| }^{2}\right)\right]\\ & = & \displaystyle \int {\rm{d}}{\boldsymbol{x}}{\rm{D}}\hat{{\boldsymbol{x}}}\exp \left[{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ia}}{\hat{x}}_{i}^{a}\left(-{x}_{i}^{a}+\displaystyle \sum _{j}{J}_{{ij}}\phi ({x}_{j}^{a})\right)\right.\\ & & \left.-\beta \eta \displaystyle \sum _{a}\parallel {{\boldsymbol{x}}}^{a}{\parallel }^{2}\right],\end{array}\end{eqnarray}$
where to arrive at the second equality, the Hubbard–Stratonovich transformation is used [17], and i, a denote the neuron and replica index, respectively. The neuron index runs from 1 to N, while the replica index runs from 1 to n. We write a shorthand ${\rm{D}}\hat{{\boldsymbol{x}}}\equiv {\prod }_{i=1}^{N}{\prod }_{a=1}^{n}{\rm{D}}{x}_{i}^{a}$ where ${\rm{D}}\hat{x}\equiv \,{{\rm{e}}}^{-\displaystyle \frac{1}{2}{\hat{x}}^{2}}{\rm{d}}\hat{x}/\sqrt{2\pi }$ being the Gaussian measure, and we call $\hat{x}$ as a response field [15]. We also denote dx as a shorthand for ${\prod }_{i=1}^{N}{\prod }_{a=1}^{n}{\rm{d}}{x}_{i}^{a}$, where ${x}_{i}^{a}\in {\mathbb{R}}$. Therefore, $-\beta f={\mathrm{lim}}_{n\to 0}\tfrac{\mathrm{ln}\left\langle {Z}^{n}\right\rangle }{{Nn}}$ [20], where $\left\langle \cdot \right\rangle $ denotes the disorder average over J. The neural dynamics are much faster than the coupling dynamics, in which we assume a stationary limit of fixed J, and thus the quenched disorder average is required. But if both dynamics evolve in similar time scales, an enlarged state space may be considered, and we leave this issue to future works.In the course of replica analysis (see details in appendix A ), two order parameters are naturally introduced as follows,4 ) and equation (8 )]. As the first level of approximation, we assume the replica symmetric ansätz to order parameters Qab = qδab + Q(1 − δab) and Rab = rδab + R(1 − δab), whose physical meaning is explained in more details in appendix A . Under this approximation, the free energy is given by
$\begin{eqnarray}{Q}^{{ab}}=\displaystyle \frac{1}{N}\displaystyle \sum _{i}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b}),\end{eqnarray}$
$\begin{eqnarray}{R}^{{ab}}=\displaystyle \frac{1}{N}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}\phi ({x}_{i}^{b}),\end{eqnarray}$
where ${\hat{x}}_{i}^{a}$ acts as a response field, whose name is inspired by the analysis using DMFT [15] and explained below. Briefly, this response field emerges due to the linearization of the quadratic terms in the Hamiltonian [see equation ( $\begin{eqnarray}\begin{array}{rcl}-\beta f & = & \displaystyle \frac{1}{2}Q\hat{Q}-q\hat{q}+R\hat{R}-r\hat{r}-\mathrm{ln}\sigma +\displaystyle \frac{1}{2}\beta {g}^{2}\gamma \left({r}^{2}-{R}^{2}\right)\\ & & +\displaystyle \int \left({\rm{D}}{u}{\rm{D}}{v}\right)\mathrm{ln}I,\end{array}\end{eqnarray}$
where $\sigma \equiv \sqrt{1+{g}^{2}\beta (q-Q)}$, and $\hat{Q}$, $\hat{q}$, $\hat{R}$ and $\hat{r}$ are conjugated order parameters. The integral $I\equiv \int {\rm{d}}x{{\rm{e}}}^{{ \mathcal H }(x)}$, where $\begin{eqnarray}\begin{array}{rcl}{ \mathcal H }(x) & \equiv & -\beta \eta {x}^{2}+\displaystyle \frac{1}{2}\left(2\hat{q}-\hat{Q}\right){\phi }^{2}(x)\\ & & +\left(\sqrt{\tfrac{{g}^{2}\beta Q\hat{Q}-{\hat{R}}^{2}}{{g}^{2}\beta Q}}u+\displaystyle \frac{\hat{R}}{g\sqrt{\beta Q}}v\right)\phi (x)\\ & & -\displaystyle \frac{1}{2{\sigma }^{2}}{\left(g\sqrt{\beta Q}v+(\hat{r}-\hat{R})\phi (x)-\sqrt{\beta }x\right)}^{2}.\end{array}\end{eqnarray}$
In the large N limit, we can use the saddle-point approximation (also called the Laplace method) to derive the closed equations the order parameters must obey. Therefore, by setting the derivatives of the replica free energy with respect to the order parameters zero, we obtain the following compact self-consistent equations (see appendix B for details)C ).
$\begin{eqnarray}q=\left[\left\langle {\phi }^{2}\right\rangle \right],\end{eqnarray}$
$\begin{eqnarray}Q=\left[{\left\langle \phi \right\rangle }^{2}\right],\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}\hat{q} & = & -\displaystyle \frac{{gk}}{2}+\displaystyle \frac{{g}^{2}{k}^{2}Q}{2}+\displaystyle \frac{{gk}}{2{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(1,1,-2)\left[\left\langle {\phi }^{2}\right\rangle \right]\\ & & +\displaystyle \frac{{gk}}{{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(0,-1,1)\left[{\left\langle \phi \right\rangle }^{2}\right]+\displaystyle \frac{{k}^{2}}{2}\left(1-2{gkQ}\right)\left[\left\langle {x}^{2}\right\rangle \right]\\ & & +\displaystyle \frac{{gk}\sqrt{\beta }}{{\sigma }^{2}}f(0,1,-2)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right]\\ & & +\displaystyle \frac{{gk}\sqrt{\beta }}{{\sigma }^{2}}f(-1,0,2)\left[\left\langle x\phi \right\rangle \right]\\ & & +{{gk}}^{3}Q\left[{\left\langle x\right\rangle }^{2}\right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}\hat{Q} & = & {g}^{2}{k}^{2}Q+\displaystyle \frac{2{gk}}{{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(0,1,-1)\left[\left\langle {\phi }^{2}\right\rangle \right]\\ & & +\displaystyle \frac{{gk}}{{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(1,-3,2)\left[{\left\langle \phi \right\rangle }^{2}\right]-2{{gk}}^{3}Q\left[\left\langle {x}^{2}\right\rangle \right]\\ & & -\displaystyle \frac{2{gk}\sqrt{\beta }}{{\sigma }^{2}}f(1,-2,2)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right]+{k}^{2}\left(1+2{gkQ}\right)\left[{\left\langle x\right\rangle }^{2}\right]\\ & & +\displaystyle \frac{2{gk}\sqrt{\beta }}{{\sigma }^{2}}f(0,-1,2)\left[\left\langle x\phi \right\rangle \right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}r & = & -\displaystyle \frac{1}{{\sigma }^{2}}f(1,0,-1)\left[\left\langle {\phi }^{2}\right\rangle \right]+\displaystyle \frac{1}{{\sigma }^{2}}f(0,1,-1)\left[{\left\langle \phi \right\rangle }^{2}\right]\\ & & +\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left(1-{gkQ}\right)\left[\left\langle \phi x\right\rangle \right]+\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}{gkQ}\left[\left\langle \phi \right\rangle \left\langle x\right\rangle \right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}R & = & -\displaystyle \frac{1}{{\sigma }^{2}}f(0,1,-1)\left[\left\langle {\phi }^{2}\right\rangle \right]-\displaystyle \frac{1}{{\sigma }^{2}}f(1,-2,1)\left[{\left\langle \phi \right\rangle }^{2}\right]\\ & & -\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}{gkQ}\left[\left\langle x\phi \right\rangle \right]+\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left(1+{gkQ}\right)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\hat{r}=\beta {g}^{2}\gamma r,\end{eqnarray}$
$\begin{eqnarray}\hat{R}=\beta {g}^{2}\gamma R,\end{eqnarray}$
where $k\equiv \tfrac{g\beta }{{\sigma }^{2}}$ and $f(a,b,c)\equiv a\hat{r}+b\hat{R}+{cgkQ}\left(\hat{r}-\hat{R}\right)$. In addition, two kinds of averages are specified. One is the disorder average $\left[\cdot \right]\equiv \int {\rm{D}}u{\rm{D}}v\cdot $, and the other is the thermal average $\left\langle \cdot \right\rangle \equiv \tfrac{\int {\rm{d}}x{{\rm{e}}}^{{ \mathcal H }(x)}\cdot }{\int {\rm{d}}x{{\rm{e}}}^{{ \mathcal H }(x)}}$. ${ \mathcal H }(x)$ plays the role of the effective Hamiltonian of our model. We emphasize that this thermal average is only defined in this saddle-point equation, or other quantities that can be expressed as a function of order parameters; otherwise, ⟨·⟩ should be referred to as the average over the coupling statistics. When γ = 0 (i.i.d. scenario), $\hat{r},\hat{R}$, and f(a, b, c) vanish, the above saddle point equation can be greatly simplified (see appendix We finally remark that the above two kinds of order parameters arising from the quenched disorder average have clear physical meanings. First, q − Q characterizes the activity fluctuation in the neural population, which can be directly measured in neural circuits. Second, Rab can be interpreted as the response function. More precisely, the steady-state receives a perturbation of synaptic currents (e.g., denoted by Ia, where a can be assumed as a state index [20]), and the linear response $\tfrac{\partial \langle {\phi }_{b}\rangle }{\partial {I}_{a}}$ characterizes how the system reacts to the small perturbation. φb is the mean-field activity of the state b. Note that the average ⟨·⟩ is defined under equation (8 ), which leads to ${R}^{{ab}}=\langle {\hat{x}}^{a}{\phi }_{b}\rangle $. Therefore we explain Rab as a linear response in physics. We shall support this picture with theoretical arguments and numerical simulations in the next section.
4. Results and discussion
4.1. Equilibrium replica analysis reveals the continuous nature of the chaos transition
The zero temperature limit selects the ground state of the Boltzmann measure [equation (7 )], which captures the statistics of the steady-state solutions of the original non-gradient dynamics [equation (1 )]. An explicit form of the Lyapunov function that is monotonically decreasing over time can only be identified provided that the neural coupling is symmetric, and only in this special case, the Lyapunov function reduces to an Ising-model like Hamiltonian, as encountered in standard Hopfield networks [28]. We thus remark that the quasi-potential defined in equation (4 ) is not the physical potential of the original dynamics, yet capturing only the steady-state properties of the dynamics, e.g., the low- (or zero-) speed landscape. In this sense, not all characteristics of non-gradient dynamics are included in our approximate potential description, e.g., the transient behavior or the temporal evolution of auto-correlation even in the time translation invariant regime is not captured. However, the statistics of fixed-point solutions can be well captured by the quasi-potential approach.
The average energy is an indicator of whether the RNN dynamics are trapped in fixed points. In other words, steady states are achievable provided that the average energy can be optimized to the ground state zero value. Without loss of generality, we consider the independent setting γ = 0 and set η = 0. As shown in figure 2, with increasing value of β, the energy decreases to 0, implying that the ground state can be achieved in a very large β. When β = 10000, the energy becomes less than 10−4, suggesting that it is reasonable to set β = 10000 for the zero temperature limit considered in our numerical solutions of the self-consistent equation [see equation (13a )]. We also show the ℓ2 norm of the network activity in figure 2. The norm displays different magnitudes before and after the onset of chaos. We also plot a comparison between the gradient Langevin dynamics [see equation (5 )] at a very low temperature and the original dynamics in figure 3. The approximate gradient dynamics are able to reach the fixed points of the original dynamics in the presence of relatively small g and remain there; in other words, the chaos is made stable. In the original dynamics, because of instability (at least one eigenvalue (real part) of the state-dependent Jacobian is positive), those fixed points outline the realm of chaotic dynamics. It is intuitively expected that as the temperature for the Langevin dynamics goes to zero, both dynamics share the same set of fixed points [see also the rationale we explained earlier in the previous paragraph and that below equation (6 )]. We leave a systematic exploration of this point in a future work.
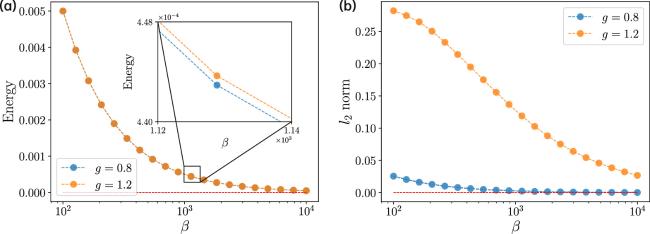
Figure 2. The average energy (a) and ℓ2 norm (b) of network activity versus the inverse temperature β in the i.i.d. scenario γ = 0 with η = 0. The orange and the blue curves represent the setting g = 0.8 and g = 1.2, respectively. The red dashed line denotes the ground state energy. Two lines of g = 0.8 and g = 1.2 are nearly indistinguishable. |
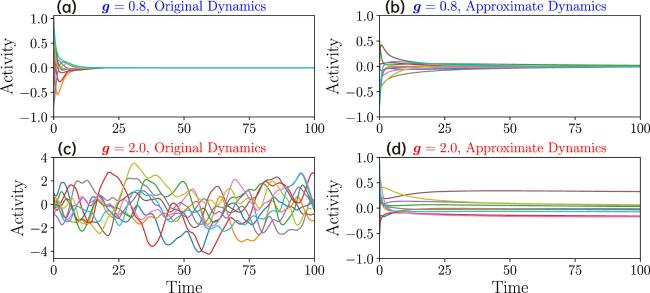
Figure 3. Dynamics comparison between the original non-gradient one and approximate gradient one at zero temperature. Representative trajectories of x are shown. Note that when g > 1 and γ = 0, the approximate dynamics flow to fixed points, which outline the realm of the original chaotic dynamics. |
With a finite temperature, the low-speed solutions of the original dynamics could also be studied. For the remaining analysis, we focus on a very large β (e.g., β = 104) and set η = 0 unless otherwise stated. Varying the control parameters g and γ, we plot the profiles of all order parameters (q, Q, r, R) in figure 4.
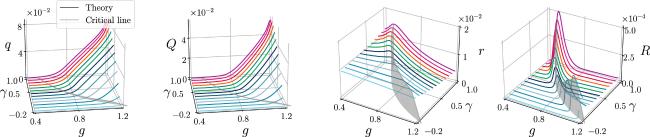
Figure 4. Order parameter profile as a function of gain parameters g and symmetric degree γ. g is varied from 0.4 to 1.2, and γ is varied from −0.2 to 1.0 with an interval of 0.1. The colors of curves correspond to the different γ values. The grey vertical plane specifies the location of the critical line $g\left(\gamma +1\right)=1$ [19]. |
Our replica analysis reveals exactly the order-to-chaos transition [19]. When $g\lt \tfrac{1}{1+\gamma }$, the zero fixed-point uniquely dominates the phase space, resulting in vanishing q and Q, as expected from the physical definition of the order parameters. Once $g\gt \tfrac{1}{1+\gamma }$, q and Q increase rapidly but continually from zero, indicating the emergence of self-sustained collective activity. This coincides with the known picture of exponentially growing topological complexity [24] and the positive maximal Lyapunov exponent [17, 18, 29]. It would be interesting to count the stationary points of our potential, rather than using the hard-to-compute Kac–Rice formula [24], which we leave for future thorough work [22]. Our method thus provides a relatively simple way to access the dynamics landscape in the steady-state limit. We remark that the steady-state distribution of the network activity for the original non-gradient dynamics does not have an analytic form to date.
4.2. Response order parameter for non-equilibrium steady states
Let us now look at the associated order parameters involving the response field $\hat{x}$, which emerges due to the linearization of the quadratic terms in the Hamiltonian (see details in appendix A ). This response field is similar to that used to enforce the dynamics equation in a field-theoretic formula of the stochastic dynamics [15]. However, in our current setting, the response field is time-independent, as only steady-state properties are focused on in this work. Therefore, we argue that R and r bear the same physical meaning with the steady-state integrated response function in the DMFT language [15]. Let us explain in detail. Based on the derivation of DMFT in our recent work [15], we have the one-dimensional mean-field dynamics equation:
$\begin{eqnarray}\displaystyle \frac{{\rm{d}}x(t)}{{\rm{d}}t}=-x(t)+\gamma {g}^{2}{\int }_{0}^{\infty }R(t,t^{\prime} )\phi (t^{\prime} ){\rm{d}}t^{\prime} +\omega (t),\end{eqnarray}$
where $R(t,t^{\prime} )=\tfrac{\partial \langle \phi (x(t))\rangle }{\partial I(t^{\prime} )}$ is the two-time response function (I is an external perturbation), $\langle \omega (t)\omega (t^{\prime} )\rangle ={g}^{2}C(t,t^{\prime} )$, and $C(t,t^{\prime} )=\langle \phi (t)\phi (t^{\prime} )\rangle $ where the average is done in the dynamical mean-field sense.In the steady-state, we have the property of time translation invariance $R(t,t^{\prime} )=R(t-t^{\prime} )$, and thus we can simplify the second term in the right-hand side of equation (14 ) as follows,16 ). Therefore, correlation and response functions are self-consistently given by
$\begin{eqnarray}{\int }_{0}^{\infty }R(t,t^{\prime} )\phi (t^{\prime} ){\rm{d}}t^{\prime} ={\int }_{0}^{\infty }R(u)\phi (t-u){\rm{d}}u\to {R}_{\mathrm{int}}{\phi }^{* },\end{eqnarray}$
where ${R}_{\mathrm{int}}\,=\,{\int }_{0}^{\infty }R(u){\rm{d}}{u}$ is the time integral of R(t), and φ* denotes the steady-state value. Finally, we will obtain the following steady-state solution, $\begin{eqnarray}{x}^{* }={\omega }^{* }+w{\phi }^{* },\end{eqnarray}$
where w ≡ g2γRint, and ω* denotes a noise sampled from ${ \mathcal N }\left(0,{g}^{2}C\right)$. For each noise sample, x* and φ* ≡ φ(x*) denote the optimal values satisfying equation ( $\begin{eqnarray}\begin{array}{rcl}C & = & \langle {\left({\phi }^{* }\right)}^{2}{\rangle }_{\omega },\\ {R}_{\mathrm{int}} & = & \langle \phi ^{\prime} \left({\omega }^{* }+w{\phi }^{* }\right)\left(1+{{wR}}_{\mathrm{int}}\right){\rangle }_{\omega },\end{array}\end{eqnarray}$
where the average is done by drawing noise samples from ${ \mathcal N }\left(0,{g}^{2}C\right)$.A numerical iteration of equation (17 ) gives us the fixed-point of (C, Rint), which is plotted in figure 5. This corresponds exactly to the behavior of q (or Q), and even the behavior of the response order parameter derived using our quasi-potential method. We remark that our method takes an optimization angle, rather than the path integral angle. Therefore, it is reasonable to define and derive the order parameters in equilibrium ensemble theory (such as Boltzmann canonical ensemble here) and conclude the order-to-chaos transition is of the continuous type. Most interestingly, we can relate the replica overlap matrix to the observable neural activity, e.g., q − Q measures the activity fluctuation, and r − R measures the response of the system.
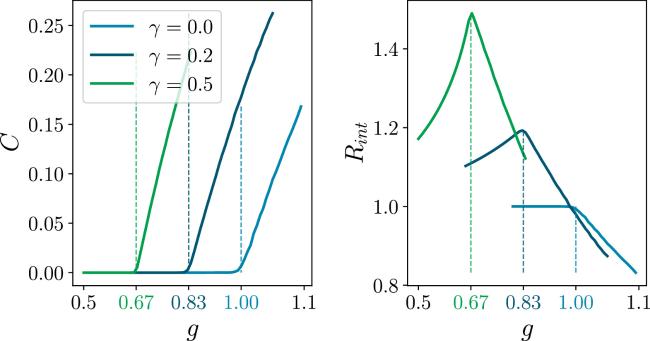
Figure 5. The behavior of correlation function C and response function Rint derived from the DMFT method [15]. We choose γ = 0.0, 0.2, 0.5, and g varies from 0.5 to 1.1 in the simulations. The vertical dashed lines denote the critical points for each γ value. |
In fact, r and R display a peak at the transition point. This peak is an indicator of continuous dynamics transition and may be related to the divergence of the relaxation time-scale of the auto-correlation function [18, 19]. Most interestingly, the decay behavior of the response function on both sides of the transition looks very different, and on the chaotic side, the response decays more slowly. An earlier work revealed that the memory lifetime of the network under a linear decoder decreases more slowly on the chaotic side than on the non-chaotic side [30]. This shows that the response order parameters revealed in our current work have a deep connection to other performance metrics of random neural networks, and they may share the same mathematical foundation. We thus conclude that the dynamics at the edge of chaos are more responsive than at other locations in the phase diagram. The edge of chaos has thus great computational benefits, even a bit far away from the transition point to the chaotic regime [17, 31, 32]. Surprisingly, this is also consistent with the experimental data of cortical electrodynamics [33], which claimed the information richness occurs at the edge of chaos, and the conscious brain states are located near to the edge of chaos but not deep in the chaotic regime (see figure 2 in the recent work [33]). We conclude that this peak of the response function is a meaningful byproduct of our theory, and moreover an indicator of the edge of chaos.
A careful inspection of the saddle-point equation [see equation (13a )] leads to the following concise relationship between q − Q (fluctuation) and r − R (response):
$\begin{eqnarray}r-R=\displaystyle \frac{\sqrt{\beta }{\sigma }_{x\phi }}{1+\beta {g}^{2}(q-Q)(1+\gamma )},\end{eqnarray}$
where σxφ = [⟨xφ⟩] − [⟨x⟩⟨φ⟩], characterizing the current-activity correlation. Interestingly, the current-activity correlation behaves as an approximately linear function of the activity variance (figure 6). The relation between the response and fluctuation is quite non-linear, and at some location, there exhibits a peak that indicates the transition (figure 6). It is thus very interesting in future works to derive a non-equilibrium linear response theory.
Figure 6. Fluctuation-response relationship for non-equilibrium steady states. The plotted order parameters follow the saddle-point equation derived in the main text [see equation ( |
4.3. Scaling behavior of order parameters in the zero temperature limit
In the zero temperature limit, we have to consider the following scaling behavior guaranteeing a finite value of free energy when β → ∞ [see equation (11 )].F ).
$\begin{eqnarray}\begin{array}{rcl}q-Q & \to & \displaystyle \frac{\chi }{\beta },\quad \hat{Q}\to {\beta }^{2}\hat{Q},\\ 2\hat{q}-\hat{Q} & \to & -2\beta \hat{\chi },\quad r\to \sqrt{\beta }\tilde{r},\\ R-r & \to & \displaystyle \frac{\xi }{\sqrt{\beta }},\quad \hat{R}\to {\beta }^{\tfrac{3}{2}}\kappa ,\\ \hat{r}-\hat{R} & \to & \beta {\rm{\Gamma }},\end{array}\end{eqnarray}$
where the new set of order parameters includes q, χ, $\hat{Q}$, $\hat{\chi }$, $\tilde{r}$, ξ, κ, and Γ, which are all of order one in magnitude. In the above scaling, one can derive a finite value of free energy density, from which the saddle point equation can also be derived (details are shown in appendix The qualitative behavior of the new order parameter set is similar to that observed in the large β case (figure 7). The activity order parameter q becomes non-zero when the transition point is crossed to right-hand side, while χ has a sharp decrease when g goes below the transition point, implying the activity variance is strongly reduced when the dynamics have stable solutions. The behavior of $\tilde{r}$ is qualitatively the same as that of q in the shown regime, but we remark that they will develop a peak before reaching zero again with further increasing g. The order parameter $-\xi ={\mathrm{lim}}_{\beta \to \infty }\sqrt{\beta }(r-R)$ displays a peak at the transition point.
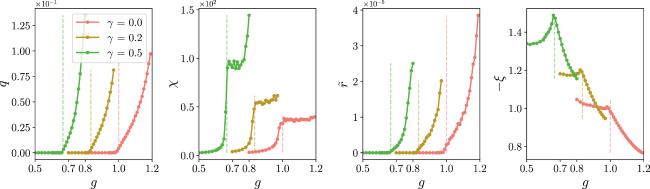
Figure 7. Order parameters as a function of increasing g for different values of γ. The results are obtained by solving the saddle-point equation in the zero temperature limit [see equation ( |
5. Concluding remarks
In this paper, we provide a relatively simple way to study non-equilibrium dynamics, by proposing a quasi-potential. Under this potential, we derive the stochastic dynamics to implement the optimization of searching for the low-speed region of the phase space. In the zero temperature limit, only the fixed points are considered, and thus our canonical ensemble theory yields a good description of the original non-potential dynamics in the long time limit. More precisely, the low (zero)-speed landscape of the phase space can be analytically studied, which is relevant to our mechanistic understanding of recurrent neural dynamics, which can be adaptive, hierarchical, and noisy. This equilibrium transformation allows for using the Boltzmann measure to describe the low-speed landscape, as could be derived from the Fokker–Planck equation of the corresponding stochastic dynamics of the optimization [1]. Due to the quenched disorder present in our model, the replica method can be readily adapted as well.
The new finding is that two physically relevant order parameters are derived from our canonical ensemble calculation. One is activity-related, which exactly reproduces the order-to-chaos transition phenomenon, previously derived by using more complicated DMFT and random matrix theory [15, 18, 19, 25]. The other is response related, which shows a peak at the very transition point, demonstrating the computation benefits of the edge of chaos. The continuous nature of this chaos transition is confirmed by our theory as well. This transition is related to supersymmetry breaking in a field-theoretic representation of the dynamics in an action [34]. Remarkably, we relate the replica overlap matrix to measurable fluctuations and responses in non-equilibrium steady states of non-gradient neural dynamics.
Our work reveals a quasi-potential landscape behind non-gradient Langevin dynamics (or deterministic dynamics). This could inspire several important future directions. First, a complete picture of this landscape can be studied, as powerful equilibrium approaches can be leveraged, such as large deviation analysis [21], and landscape geometry analysis [35]. It would be very interesting to study the relationship between the distribution of equilibria and the onset of chaos in our framework, which we leave for a forthcoming paper [22]. Second, one can ask what is the quasi-potential of a coupled-dynamics system where the dynamics of constituent elements can be divided into several levels of different time scales. An enlarged state space is required to be introduced. Lastly, one could modify the quasi-potential dynamics to approximate the original non-gradient dynamics with increasing precision.
To sum up, our quasi-potential method provides a simple yet powerful tool to understand the non-equilibrium steady states, especially those without the equilibrium limit (non-gradient stochastic dynamics). Our method allows for order parameters to be defined in the canonical ensemble, determination of the transition type, and characterization of fluctuation-response relationship around the dynamics transition, thereby laying down a mathematical foundation of steady-state landscape of high-dimensional neural dynamics. We build a solid bridge from equilibrium ensemble theory to non-equilibrium non-gradient dynamics, and this optimization angle as a fresh route toward understanding non-equilibrium brain dynamics would prove fruitful in future studies.
Our approach does not rely on the special form of non-linear dynamics, as long as the speed of the dynamics can be identified, which already includes a broad range of neural dynamics models [17, 36]. In our framework, it would be very promising to treat the competition dynamics of many species in ecosystems [37–39], high-dimensional dynamics of random optimization [40, 41], high-dimensional gradient flow in machine learning [42], and adaptive, hierarchical and noisy neural dynamics in neuroscience [29, 36, 43–45]. The only limitation is that the transient behavior before the steady-state is reached and the steady-state dynamics could not be captured by our equilibrium approximation, and in that case, integro-differential equations or time-translation-invariant dynamics are required to solve with expensive computational cost [15]. Even if the dynamics contain slowly evolving couplings, we can also treat this as a quenched disorder that can be averaged resulting in a self-averaged free energy, from which transitions can be detected and analyzed. As some types of dynamics can not be accessed by DMFT, or the resultant integro-differential equations for correlation and response functions are hard to solve, our quasi-potential method is a promising alternative starting point to understanding the steady-state landscape of general non-equilibrium dynamics [46].
Acknowledgments
We would like to thank Zijian Jiang, Yang Zhao and Wenkang Du for the helpful discussions in earlier stages of this project. This research was supported by the National Natural Science Foundation of China under Grant No. 12122515 (HH), and Guangdong Provincial Key Laboratory of Magnetoelectric Physics and Devices (Grant No. 2022B1212010008), and Guangdong Basic and Applied Basic Research Foundation (Grant No. 2023B1515040023).
Appendix A. Details of replica calculation
Starting from equation (8 ), we perform the Hubbard–Stratonovich (HS) transformation ${{\rm{e}}}^{-\tfrac{1}{2}{{ab}}^{2}}=\int {\rm{D}}\hat{x}{{\rm{e}}}^{{\rm{i}}\sqrt{a}b\hat{x}}$ for a > 0, to linearize the quadratic terms and have
$\begin{eqnarray}\begin{array}{rcl}{Z}^{n} & = & \int {\rm{d}}{\boldsymbol{x}}{\rm{D}}\hat{{\boldsymbol{x}}}\exp \left[{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ia}}{\hat{x}}_{i}^{a}\left(-{x}_{i}^{a}\right.\right.\\ & & \left.\left.+\displaystyle \sum _{j}{J}_{{ij}}\phi ({x}_{j}^{a})\right)-\beta \eta \displaystyle \sum _{a}\parallel {{\boldsymbol{x}}}^{a}{\parallel }^{2}\right],\end{array}\end{eqnarray}$
where we define ${\rm{D}}\hat{x}\equiv {{\rm{e}}}^{-\displaystyle \frac{1}{2}{\hat{x}}^{2}}{\rm{d}}\hat{x}/\sqrt{2\pi }$ as the Gaussian measure, and we call $\hat{x}$ as a response field [15]. We define i, j as the neuron index and a, b as the replica index. The neuron index runs from 1 to N, while the replica index runs from 1 to n. In addition, ${\rm{d}}{\boldsymbol{x}}\equiv {\prod }_{i,a}{\rm{d}}{x}_{i}^{a}$ and ${\rm{D}}\hat{{\boldsymbol{x}}}\equiv {\prod }_{i,a}{\rm{D}}{\hat{x}}_{i}^{a}$.Before implementation of the quenched disorder average over the coupling statistics, it is convenient to separate the connection matrix into a symmetric part JS and an anti-symmetric part JA [12],
$\begin{eqnarray}{\boldsymbol{J}}={{\boldsymbol{J}}}^{{\rm{S}}}+\rho {{\boldsymbol{J}}}^{{\rm{A}}},\end{eqnarray}$
where by definition ${J}_{{ij}}^{{\rm{S}}}={J}_{{ji}}^{{\rm{S}}}$ and ${J}_{{ij}}^{{\rm{A}}}=-{J}_{{ji}}^{{\rm{A}}}$, and their variances are defined as follows, $\begin{eqnarray}\left\langle {\left({J}_{{ij}}^{{\rm{S}}}\right)}^{2}\right\rangle =\left\langle {\left({J}_{{ij}}^{{\rm{A}}}\right)}^{2}\right\rangle =\displaystyle \frac{{g}^{2}}{N}\displaystyle \frac{1}{1+{\rho }^{2}}.\end{eqnarray}$
Both parts are uncorrelated. It then follows that $\begin{eqnarray}\left\langle {J}_{{ij}}{J}_{{ji}}\right\rangle \,=\,\displaystyle \frac{{g}^{2}}{N}\displaystyle \frac{1-{\rho }^{2}}{1+{\rho }^{2}}=\displaystyle \frac{{g}^{2}}{N}\gamma ,\end{eqnarray}$
where the relationship between $\rho$ and γ is given below, $\begin{eqnarray}\rho =\sqrt{\displaystyle \frac{1-\gamma }{1+\gamma }}.\end{eqnarray}$
Defining $\left\langle \cdot \right\rangle $ as the quenched disorder average, we haveA6 ),
$\begin{eqnarray}\begin{array}{rcl}\left\langle {Z}^{n}\right\rangle & = & \displaystyle \int {\rm{d}}{\boldsymbol{x}}{\rm{D}}\hat{{\boldsymbol{x}}}\exp \left[-{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ia}}{x}_{i}^{a}{\hat{x}}_{i}^{a}-\beta \eta \displaystyle \sum _{a}\parallel {{\boldsymbol{x}}}^{a}{\parallel }^{2}\right]\\ & & \times \left\langle \exp \left[{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ia}}{\hat{x}}_{i}^{a}\displaystyle \sum _{j}{J}_{{ij}}\phi ({x}_{j}^{a})\right]\right\rangle .\end{array}\end{eqnarray}$
The quenched disorder average is first completed as follows, $\begin{eqnarray}\begin{array}{l}\left\langle \exp \left[{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ij}}{J}_{{ij}}\displaystyle \sum _{a}{\hat{x}}_{i}^{a}\phi ({x}_{j}^{a})\right]\right\rangle \\ =\,\left\langle \exp \left[{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ij}}\left({J}_{{ij}}^{{\rm{S}}}+\rho {J}_{{ij}}^{{\rm{A}}}\right)\displaystyle \sum _{a}{\hat{x}}_{i}^{a}\phi ({x}_{j}^{a})\right]\right\rangle \\ =\,\exp \left[-\displaystyle \frac{1}{2}\beta \displaystyle \frac{{g}^{2}}{N}\displaystyle \frac{1}{1+{\rho }^{2}}\displaystyle \sum _{i\lt j}\displaystyle \sum _{{ab}}\left({\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{j}^{a})\phi ({x}_{j}^{b}),\left.+{\hat{x}}_{i}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{j}^{a})\phi ({x}_{i}^{b})+{\hat{x}}_{j}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{i}^{a})\phi ({x}_{j}^{b})+{\hat{x}}_{j}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b})\right)\right.\right]\\ \quad \times \exp \left[-\displaystyle \frac{1}{2}\beta \displaystyle \frac{{g}^{2}}{N}\displaystyle \frac{{\rho }^{2}}{1+{\rho }^{2}}\displaystyle \sum _{i\lt j}\displaystyle \sum _{{ab}}\left({\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{j}^{a})\phi ({x}_{j}^{b})-{\hat{x}}_{i}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{j}^{a})\phi ({x}_{i}^{b}),\left.-{\hat{x}}_{j}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{i}^{a})\phi ({x}_{j}^{b})+{\hat{x}}_{j}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b})\right)\right.\right]\\ =\,\exp \left[-\displaystyle \frac{1}{2}\beta \displaystyle \frac{{g}^{2}}{N}\displaystyle \sum _{i\ne j}\displaystyle \sum _{{ab}}\left(\displaystyle \frac{1}{1+{\rho }^{2}}\left({\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{j}^{a})\phi ({x}_{j}^{b})+{\hat{x}}_{i}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{j}^{a})\phi ({x}_{i}^{b})\right)+\displaystyle \frac{{\rho }^{2}}{1+{\rho }^{2}}\left({\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{j}^{a})\phi ({x}_{j}^{b}\left.-{\hat{x}}_{i}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{j}^{a})\phi ({x}_{i}^{b})\right)\right.\right)\right]\\ =\,\exp \left[-\displaystyle \frac{1}{2}\beta \displaystyle \frac{{g}^{2}}{N}\displaystyle \sum _{{ij}}\displaystyle \sum _{{ab}}\left({\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}\phi ({x}_{j}^{a})\phi ({x}_{j}^{b}),\left.+\gamma {\hat{x}}_{i}^{a}{\hat{x}}_{j}^{b}\phi ({x}_{j}^{a})\phi ({x}_{i}^{b})\right)\right.\right]\\ =\,\exp \left[-\displaystyle \frac{1}{2}\beta {g}^{2}\displaystyle \sum _{{ab}}{Q}^{{ab}}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}-\displaystyle \frac{1}{2}\beta {g}^{2}N\gamma \displaystyle \sum _{{ab}}{R}^{{ab}}{R}^{{ba}}\right],\end{array}\end{eqnarray}$
where we are left with only γ (whose value can now take from −1 to 1, although γ = −1 is ill-defined for $\rho$), and we treat in our model the diagonal elements of the connection matrix negligible compared to the contribution from off-diagonal elements of the connection matrix, because of large N limit. To arrive at the last step, we have to introduce the following order parameters $\begin{eqnarray}{Q}^{{ab}}=\displaystyle \frac{1}{N}\displaystyle \sum _{i}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b}),\end{eqnarray}$
$\begin{eqnarray}{R}^{{ab}}=\displaystyle \frac{1}{N}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}\phi ({x}_{i}^{b}).\end{eqnarray}$
Hence, we need to insert the following identity in equation ( $\begin{eqnarray}\begin{array}{rcl}1 & = & \displaystyle \prod _{a\leqslant b}\displaystyle \int {\rm{d}}{Q}^{{ab}}\delta \left({Q}^{{ab}}-\displaystyle \frac{1}{N}\displaystyle \sum _{i}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b})\right)\displaystyle \prod _{{ab}}\displaystyle \int {\rm{d}}{R}^{{ab}}\delta \left({R}^{{ab}}-\displaystyle \frac{1}{N}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}\phi ({x}_{i}^{b})\right)\\ & = & \displaystyle \int \displaystyle \frac{{\rm{d}}{\boldsymbol{Q}}{\rm{d}}\hat{{\boldsymbol{Q}}}{\rm{d}}{\boldsymbol{R}}{\rm{d}}\hat{{\boldsymbol{R}}}}{{\left(2\pi \right)}^{D}}\exp \left[-{\rm{i}}\displaystyle \sum _{a\leqslant b}{Q}^{{ab}}{\hat{Q}}^{{ab}}-{\rm{i}}\displaystyle \sum _{{ab}}{R}^{{ab}}{\hat{R}}^{{ab}}+{\rm{i}}\displaystyle \frac{1}{N}\displaystyle \sum _{i}\displaystyle \sum _{a\leqslant b}{\hat{Q}}^{{ab}}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b})+{\rm{i}}\displaystyle \frac{1}{N}\displaystyle \sum _{{ab}}{\hat{R}}^{{ab}}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}\phi ({x}_{i}^{b})\right]\\ & = & \displaystyle \int \displaystyle \frac{{\rm{d}}{\boldsymbol{Q}}{\rm{d}}\hat{{\boldsymbol{Q}}}{\rm{d}}{\boldsymbol{R}}{\rm{d}}\hat{{\boldsymbol{R}}}}{{[2\pi {\left({\rm{i}}/N\right)}^{2}]}^{D}}\exp \left[-N\displaystyle \sum _{a\leqslant b}{Q}^{{ab}}{\hat{Q}}^{{ab}}-N\displaystyle \sum _{{ab}}{R}^{{ab}}{\hat{R}}^{{ab}}+\displaystyle \sum _{i}\displaystyle \sum _{a\leqslant b}{\hat{Q}}^{{ab}}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b})+{\rm{i}}\displaystyle \sum _{{ab}}{\hat{R}}^{{ab}}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}\phi ({x}_{i}^{b})\right],\end{array}\end{eqnarray}$
where D = n2 + n(n + 1)/2, and we apply the Fourier transformation of Dirac delta function by introducing the conjugated order parameters ${\hat{Q}}^{{ab}}$, ${\hat{R}}^{{ab}}$, and rescale the order parameters as ${\hat{Q}}^{{ab}}\to -{\rm{i}}N{\hat{Q}}^{{ab}}$, Rab → − iRab and ${\hat{R}}^{{ab}}\to N{\hat{R}}^{{ab}}$ in the last step. ${\rm{d}}{\boldsymbol{Q}}{\rm{d}}\hat{{\boldsymbol{Q}}}{\rm{d}}{\boldsymbol{R}}{\rm{d}}\hat{{\boldsymbol{R}}}$ is a shorthand for ${\prod }_{a\leqslant b}{\rm{d}}{Q}^{{ab}}{\rm{d}}{\hat{Q}}_{{ab}}{\prod }_{{ab}}{\rm{d}}{R}^{{ab}}{\rm{d}}{\hat{R}}^{{ab}}$.As a result, equation (A6 ) becomes
$\begin{eqnarray}\begin{array}{l}\left\langle {Z}^{n}\right\rangle \propto \displaystyle \int {\rm{d}}{\boldsymbol{x}}{\rm{D}}\hat{{\boldsymbol{x}}}{\rm{d}}{\boldsymbol{Q}}{\rm{d}}\hat{{\boldsymbol{Q}}}{\rm{d}}{\boldsymbol{R}}{\rm{d}}\hat{{\boldsymbol{R}}}\\ \,\times \exp \left[-{\rm{i}}\sqrt{\beta }\displaystyle \sum _{{ia}}{x}_{i}^{a}{\hat{x}}_{i}^{a}-\beta \eta \displaystyle \sum _{{ia}}{\left({x}_{i}^{a}\right)}^{2}\right]\\ \,\times \exp \left[-\displaystyle \frac{1}{2}{g}^{2}\beta \displaystyle \sum _{{ab}}{Q}^{{ab}}\left(\displaystyle \sum _{i}{\hat{x}}_{i}^{a}{\hat{x}}_{i}^{b}\right)\right.\\ \,+\displaystyle \frac{1}{2}\beta {g}^{2}N\gamma \displaystyle \sum _{{ab}}{R}^{{ab}}{R}^{{ba}}\\ \,-N\displaystyle \sum _{a\leqslant b}{Q}^{{ab}}{\hat{Q}}^{{ab}}-N\displaystyle \sum _{{ab}}{R}^{{ab}}{\hat{R}}^{{ab}}\\ \,\left.+\displaystyle \sum _{i}\displaystyle \sum _{a\leqslant b}{\hat{Q}}^{{ab}}\phi ({x}_{i}^{a})\phi ({x}_{i}^{b})+{\rm{i}}\displaystyle \sum _{{ab}}{\hat{R}}^{{ab}}\displaystyle \sum _{i}{\hat{x}}_{i}^{a}\phi ({x}_{i}^{b})\right],\end{array}\end{eqnarray}$
where we have neglected the irrelevant constant due to the variable change in the integral, which does not affect the later saddle point approximation in the large N limit.Equation (A11 ) can be rewritten into a compact form,
$\begin{eqnarray}\begin{array}{rcl}\left\langle {Z}^{n}\right\rangle & \propto & \displaystyle \int {\rm{d}}{\boldsymbol{Q}}{\rm{d}}\hat{{\boldsymbol{Q}}}{\rm{d}}{\boldsymbol{R}}{\rm{d}}\hat{{\boldsymbol{R}}}\\ & & \times \exp \left[N\left(-\displaystyle \sum _{a\leqslant b}{Q}^{{ab}}{\hat{Q}}^{{ab}}-\displaystyle \sum _{{ab}}{R}^{{ab}}{\hat{R}}^{{ab}}+{ \mathcal G }\right)\right],\end{array}\end{eqnarray}$
where the model-dependent action ${ \mathcal G }$ reads, $\begin{eqnarray}\begin{array}{rcl}{ \mathcal G } & = & \mathrm{ln}\displaystyle \int {\rm{d}}{\boldsymbol{x}}{\rm{D}}\hat{{\boldsymbol{x}}}\exp \left[-{\rm{i}}\sqrt{\beta }\displaystyle \sum _{a}{x}^{a}{\hat{x}}^{a}-\beta \eta \displaystyle \sum _{a}{\left({x}^{a}\right)}^{2}\right.\\ & & -\displaystyle \frac{1}{2}{g}^{2}\beta \displaystyle \sum _{{ab}}{Q}^{{ab}}{\hat{x}}^{a}{\hat{x}}^{b}+\displaystyle \sum _{a\leqslant b}{\hat{Q}}^{{ab}}\phi ({x}^{a})\phi ({x}^{b})\\ & & \left.+\displaystyle \frac{1}{2}\beta {g}^{2}\gamma \displaystyle \sum _{{ab}}{R}^{{ab}}{R}^{{ba}}+{\rm{i}}\displaystyle \sum _{{ab}}{\hat{R}}^{{ab}}{\hat{x}}^{a}\phi ({x}^{b})\right],\end{array}\end{eqnarray}$
where dx and ${\rm{D}}\hat{{\boldsymbol{x}}}$ have been reduced to ∏adxa and ${\prod }_{a}{\rm{D}}{\hat{x}}^{a}$, respectively.To proceed, we have to assume the replica symmetric (RS) ansätz as the first level of approximation, i.e., the replica overlap matrix is permutation invariant, as is intuitively expected from the replicated partition function. This first level of approximation can be refined by going to multiple steps of replica symmetry breaking [20], provided that the theoretical prediction is in significant disagreement with numerical simulations. The RS ansätz reads Qab = qδab + Q(1 − δab), ${\hat{Q}}^{{ab}}=\hat{q}{\delta }_{{ab}}+\hat{Q}(1-{\delta }_{{ab}})$, Rab = rδab + R(1 − δab) and ${\hat{R}}^{{ab}}\,=\hat{r}{\delta }_{{ab}}+\hat{R}(1-{\delta }_{{ab}})$. We have then the following result of the averaged replicated partition function,A15 ), we use the HS transformation once again as follows,
$\begin{eqnarray}\begin{array}{l}\left\langle {Z}^{n}\right\rangle \propto \displaystyle \int {\rm{d}}Q{\rm{d}}\hat{Q}{\rm{d}}q{\rm{d}}\hat{q}{\rm{d}}R{\rm{d}}\hat{R}{\rm{d}}r{\rm{d}}\hat{r}\\ \times \,\exp \left[N\left(-\displaystyle \frac{n(n-1)}{2}Q\hat{Q}-{nq}\hat{q}-n(n-1)R\hat{R}-{nr}\hat{r}+{ \mathcal G }\right)\right],\end{array}\end{eqnarray}$
where $\begin{eqnarray}\begin{array}{rcl}{ \mathcal G } & = & \mathrm{ln}\displaystyle \int {\rm{d}}{\boldsymbol{x}}{\rm{D}}\hat{{\boldsymbol{x}}}\exp \left[-{\rm{i}}\sqrt{\beta }\displaystyle \sum _{a}{x}^{a}{\hat{x}}^{a}-\beta \eta \displaystyle \sum _{a}{\left({x}^{a}\right)}^{2}\right.\\ & & +\displaystyle \frac{1}{2}\beta {g}^{2}\gamma \left(n(n-1){R}^{2}+{{nr}}^{2}\right)\\ & & -\displaystyle \frac{1}{2}{g}^{2}\beta \left(Q{\left(\displaystyle \sum _{a}{\hat{x}}^{a}\right)}^{2}+\left(q-Q\right)\displaystyle \sum _{a}{\left({\hat{x}}^{a}\right)}^{2}\right)\\ & & +\displaystyle \frac{1}{2}\left(\hat{Q}{\left(\displaystyle \sum _{a}\phi ({x}^{a})\right)}^{2}+\left(2\hat{q}-\hat{Q}\right)\displaystyle \sum _{a}{\phi }^{2}({x}^{a})\right)\\ & & \left.+{\rm{i}}\left(\hat{R}\displaystyle \sum _{{ab}}{\hat{x}}^{a}\phi ({x}^{b})+\left(\hat{r}-\hat{R}\right)\displaystyle \sum _{a}{\hat{x}}^{a}\phi ({x}^{a})\right)\right].\end{array}\end{eqnarray}$
To linearize the quadratic terms in equation ( $\begin{eqnarray}\begin{array}{l}{{\rm{e}}}^{\displaystyle \frac{1}{2}\hat{Q}{\left(\displaystyle \sum _{a}\phi ({x}^{a})\right)}^{2}-\displaystyle \frac{1}{2}{g}^{2}\beta Q{\left(\displaystyle \sum _{a}{\hat{x}}^{a}\right)}^{2}+{\rm{i}}\hat{R}\displaystyle \sum _{{ab}}{\hat{x}}^{a}\phi ({x}^{b})}\\ =\displaystyle \int {\rm{D}}u{\rm{D}}v{{\rm{e}}}^{{\kappa }_{1}u\displaystyle \sum _{a}\phi ({x}^{a})+v\left({\kappa }_{2}\displaystyle \sum _{a}\phi ({x}^{a})+{\rm{i}}{\kappa }_{3}\displaystyle \sum _{a}{\hat{x}}^{a}\right)},\end{array}\end{eqnarray}$
where the auxiliary coefficients ${\kappa }_{1}=\sqrt{\tfrac{{g}^{2}\beta Q\hat{Q}-{\hat{R}}^{2}}{{g}^{2}\beta Q}}$, ${\kappa }_{2}=\tfrac{\hat{R}}{g\sqrt{\beta Q}}$ and ${\kappa }_{3}=g\sqrt{\beta Q}$.Therefore, we have
$\begin{eqnarray}{ \mathcal G }=\mathrm{ln}\int {\rm{D}}u{\rm{D}}v\exp \left[\displaystyle \frac{1}{2}\beta {g}^{2}\gamma \left(n(n-1){R}^{2}+{{nr}}^{2}\right)\right]{I}^{n},\end{eqnarray}$
where $\begin{eqnarray}\begin{array}{rcl}I & \equiv & \displaystyle \int {\rm{d}}x{\rm{D}}\hat{x}\exp \left[-\beta \eta {x}^{2}-{\rm{i}}\sqrt{\beta }x\hat{x}-\displaystyle \frac{1}{2}{g}^{2}\beta \left(q-Q\right){\hat{x}}^{2}\right.\\ & & +\displaystyle \frac{1}{2}\left(2\hat{q}-\hat{Q}\right){\phi }^{2}(x)+{\rm{i}}\left(\hat{r}-\hat{R}\right)\hat{x}\phi (x)\\ & & \left.+{\rm{i}}{\kappa }_{3}v\hat{x}+\left({\kappa }_{1}u+{\kappa }_{2}v\right)\phi (x)\right].\end{array}\end{eqnarray}$
We next complete the integral over ${\rm{D}}\hat{x}$ as $\begin{eqnarray}\begin{array}{l}\displaystyle \int {\rm{D}}\hat{x}\exp \left[-\displaystyle \frac{1}{2}{g}^{2}\beta \left(q-Q\right){\hat{x}}^{2}+{\rm{i}}\left({\kappa }_{3}v+\left(\hat{r}-\hat{R}\right)-\sqrt{\beta }x\right)\hat{x}\right]\\ =\,\displaystyle \frac{1}{\sigma }\exp \left[-\displaystyle \frac{1}{2}\displaystyle \frac{1}{{\sigma }^{2}}{\left({\kappa }_{3}v+(\hat{r}-\hat{R})\phi (x)-\sqrt{\beta }x\right)}^{2}\right],\end{array}\end{eqnarray}$
where $\sigma \equiv \sqrt{1+{g}^{2}\beta (q-Q)}$. Thus we obtain, $\begin{eqnarray}\begin{array}{rcl}{ \mathcal G } & = & -n\mathrm{ln}\sigma +\displaystyle \frac{1}{2}\beta {g}^{2}\gamma \left(n(n-1){R}^{2}+{{nr}}^{2}\right)\\ & & +\mathrm{ln}\displaystyle \int {\rm{D}}u{\rm{D}}{{vI}}^{n},\end{array}\end{eqnarray}$
where $I\equiv \int {\rm{d}}x{{\rm{e}}}^{{ \mathcal H }(x)}$, and $\begin{eqnarray}\begin{array}{rcl}{ \mathcal H }(x) & \equiv & -\beta \eta {x}^{2}+\displaystyle \frac{1}{2}\left(2\hat{q}-\hat{Q}\right){\phi }^{2}(x)+\left({\kappa }_{1}u+{\kappa }_{2}v\right)\phi (x)\\ & & -\displaystyle \frac{1}{2}\displaystyle \frac{1}{{\sigma }^{2}}{\left({\kappa }_{3}v+(\hat{r}-\hat{R})\phi (x)-\sqrt{\beta }x\right)}^{2},\end{array}\end{eqnarray}$
where ${ \mathcal H }(x)$ could be considered as the single-variable effective Hamiltonian of our model, which emerges after the quenched disorder is averaged out.Finally, we perform the saddle point approximation because of large N, such that $\left\langle {Z}^{n}\right\rangle \propto \int {\rm{d}}{ \mathcal O }{\rm{d}}\hat{{ \mathcal O }}{{\rm{e}}}^{N{\rm{\Phi }}({ \mathcal O },\hat{{ \mathcal O }})}\,\approx {{\rm{e}}}^{N{\rm{\Phi }}({{ \mathcal O }}^{* },{\hat{{ \mathcal O }}}^{* })}$, where ${ \mathcal O }=\{Q,q,R,r\}$ and the superscript ∗ refers to the saddle point value. The free energy can be obtained from the replica trick $-\beta f={\mathrm{lim}}_{n\to 0}\tfrac{\mathrm{ln}\left\langle {Z}^{n}\right\rangle }{{nN}}$, and therefore,
$\begin{eqnarray}\begin{array}{rcl}-\beta f & = & \displaystyle \frac{1}{2}Q\hat{Q}-q\hat{q}+R\hat{R}-r\hat{r}\\ & & -\mathrm{ln}\sigma +\displaystyle \frac{1}{2}\beta {g}^{2}\gamma \left({r}^{2}-{R}^{2}\right)+\displaystyle \int {\rm{D}}u{\rm{D}}v\mathrm{ln}I.\end{array}\end{eqnarray}$
Appendix B. Saddle-point equations
In this section, we omit the superscript ∗ on the order parameters and derive the self-consistent equations these order parameters must obey, which are the so-called saddle point equations (SDEs). The principle is to optimize the action with respect to the order parameters and their conjugated counterparts. The result is given below,
$\begin{eqnarray}q=\left[\left\langle {\phi }^{2}\right\rangle \right],\end{eqnarray}$
$\begin{eqnarray}Q=\left[{\left\langle \phi \right\rangle }^{2}\right],\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}r & = & -\displaystyle \frac{1}{{\sigma }^{2}}f(1,0,-1)\left[\left\langle {\phi }^{2}\right\rangle \right]+\displaystyle \frac{1}{{\sigma }^{2}}f(0,1,-1)\left[{\left\langle \phi \right\rangle }^{2}\right]\\ & & +\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left(1-{gkQ}\right)\left[\left\langle x\phi \right\rangle \right]+\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}{gkQ}\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}R & = & -\displaystyle \frac{1}{{\sigma }^{2}}f(0,1,-1)\left[\left\langle {\phi }^{2}\right\rangle \right]-\displaystyle \frac{1}{{\sigma }^{2}}f(1,-2,1)\left[{\left\langle \phi \right\rangle }^{2}\right]\\ & & -\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}{gkQ}\left[\left\langle x\phi \right\rangle \right]+\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left(1+{gkQ}\right)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}\hat{q} & = & -\displaystyle \frac{{gk}}{2}+\displaystyle \frac{{g}^{2}{k}^{2}Q}{2}+\displaystyle \frac{{gk}}{2{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(1,1,-2)\left[\left\langle {\phi }^{2}\right\rangle \right]\\ & & +\displaystyle \frac{{gk}}{{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(0,-1,1)\left[{\left\langle \phi \right\rangle }^{2}\right]+\displaystyle \frac{{k}^{2}}{2}\left(1-2{gkQ}\right)\left[\left\langle {x}^{2}\right\rangle \right]\\ & & +\displaystyle \frac{{gk}\sqrt{\beta }}{{\sigma }^{2}}f(0,1,-2)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right]\\ & & +\displaystyle \frac{{gk}\sqrt{\beta }}{{\sigma }^{2}}f(-1,0,2)\left[\left\langle x\phi \right\rangle \right]+{{gk}}^{3}Q\left[{\left\langle x\right\rangle }^{2}\right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}\hat{Q} & = & {g}^{2}{k}^{2}Q+\displaystyle \frac{2{gk}}{{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(0,1,-1)\left[\left\langle {\phi }^{2}\right\rangle \right]\\ & & +\displaystyle \frac{{gk}}{{\sigma }^{2}}\left(\hat{r}-\hat{R}\right)f(1,-3,2)\left[{\left\langle \phi \right\rangle }^{2}\right]-2{{gk}}^{3}Q\left[\left\langle {x}^{2}\right\rangle \right]\\ & & -\displaystyle \frac{2{gk}\sqrt{\beta }}{{\sigma }^{2}}f(1,-2,2)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right]\\ & & +\displaystyle \frac{2{gk}\sqrt{\beta }}{{\sigma }^{2}}f(0,-1,2)\left[\left\langle x\phi \right\rangle \right]\\ & & +{k}^{2}\left(1+2{gkQ}\right)\left[{\left\langle x\right\rangle }^{2}\right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\hat{r}=\beta {g}^{2}\gamma r,\end{eqnarray}$
$\begin{eqnarray}\hat{R}=\beta {g}^{2}\gamma R,\end{eqnarray}$
where $k\equiv \tfrac{g\beta }{{\sigma }^{2}}$ and $f(a,b,c)\equiv a\hat{r}+b\hat{R}+{cgkQ}\left(\hat{r}-\hat{R}\right)$, and we define disorder and thermal averages, respectively as follows, $\begin{eqnarray}\left[\bullet \right]\equiv \int {\rm{D}}u{\rm{D}}v\bullet ,\end{eqnarray}$
and $\begin{eqnarray}\left\langle \bullet \right\rangle \equiv \displaystyle \frac{\int {\rm{d}}x{{\rm{e}}}^{{ \mathcal H }(x)}\bullet }{\int {\rm{d}}x{{\rm{e}}}^{{ \mathcal H }(x)}}.\end{eqnarray}$
Note that we have used the integral identity $\int {\rm{D}}{xxf}(x)=\int {\rm{D}}{xf}^{\prime} (x)$ where f(x) is a bounded and differentiable function to write the above SDEs in the compact form.We are also interested in the average energy, whose ground state value is related to the speed level of the original dynamics. The thermodynamic relation $\left\langle E\right\rangle =\tfrac{\partial [\beta f]}{\partial \beta }$ is used to derive the following formula,
$\begin{eqnarray}\begin{array}{rcl}U & = & \displaystyle \frac{{g}^{2}}{2{\sigma }^{2}}\left(q-{gkQ}(q-Q)\right)-\displaystyle \frac{1}{2}{g}^{2}({r}^{2}-{R}^{2})\gamma \\ & & +\displaystyle \frac{1}{2{\sigma }^{2}}\left(1+2\eta {\sigma }^{2}-{gk}(q-Q)-\displaystyle \frac{2{gkQ}}{{\sigma }^{2}}\right)\left[\left\langle {x}^{2}\right\rangle \right]+\displaystyle \frac{{gkQ}}{{\sigma }^{4}}\left[{\left\langle x\right\rangle }^{2}\right]\\ & & -\displaystyle \frac{1}{2\sqrt{\beta }{\sigma }^{2}}\left(f(1,-1,0)+\displaystyle \frac{1}{{\sigma }^{2}}f(0,1,-3)\right.\\ & & \left.+{gk}(q-Q)f(-2,1,1)\right)\left[\left\langle x\phi \right\rangle \right]\\ & & -\displaystyle \frac{1}{2\sqrt{\beta }{\sigma }^{2}}\left(\displaystyle \frac{1}{{\sigma }^{2}}f(0,-1,3)+{gk}(q-Q)f(0,1,-1)\right)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right]\\ & & -\displaystyle \frac{1}{2{g}^{2}Q{\beta }^{2}}\left({\hat{R}}^{2}+{g}^{2}{k}^{2}Q(q-Q){\left(\hat{r}-\hat{R}\right)}^{2}\right.\\ & & \left.+f(0,-1,1)\left(f(0,1,1)-2{g}^{2}{k}^{2}Q(q-Q)(\hat{r}-\hat{R})\right)\right)\left[\left\langle {\phi }^{2}\right\rangle \right]\\ & & +\displaystyle \frac{1}{2{g}^{2}Q{\beta }^{2}}\left({\hat{R}}^{2}+f(0,-1,1)\left(f(0,1,1)-2{g}^{2}{k}^{2}Q(q-Q)(\hat{r}-\hat{R})\right)\right)\left[{\left\langle \phi \right\rangle }^{2}\right].\end{array}\end{eqnarray}$
To characterize the average activity level in the neural population, we also derive the ℓ2 norm of the activity as follows $\begin{eqnarray}\displaystyle \frac{1}{N}\left\langle \parallel {\boldsymbol{x}}{\parallel }^{2}\right\rangle =-\displaystyle \frac{1}{\beta }\displaystyle \frac{\partial \left(-\beta f\right)}{\partial \eta }=\left[\left\langle {x}^{2}\right\rangle \right].\end{eqnarray}$
Appendix C. Independent case γ = 0
In the case γ = 0, all the connection weights are independent and uncorrelated. Hence, the expression of the SDEs gets greatly simplified as
$\begin{eqnarray}q=\left[\left\langle {\phi }^{2}\right\rangle \right],\end{eqnarray}$
$\begin{eqnarray}Q=\left[{\left\langle \phi \right\rangle }^{2}\right],\end{eqnarray}$
$\begin{eqnarray}r=\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left(1-{gkQ}\right)\left[\left\langle x\phi \right\rangle \right]+\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}{gkQ}\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right],\end{eqnarray}$
$\begin{eqnarray}R=-\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}{gkQ}\left[\left\langle x\phi \right\rangle \right]+\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left(1+{gkQ}\right)\left[\left\langle x\right\rangle \left\langle \phi \right\rangle \right],\end{eqnarray}$
$\begin{eqnarray}\begin{array}{rcl}\hat{q} & = & -\displaystyle \frac{{gk}}{2}+\displaystyle \frac{{g}^{2}{k}^{2}Q}{2}+{{gk}}^{3}Q\left[{\left\langle x\right\rangle }^{2}\right]\\ & & +\displaystyle \frac{{k}^{2}}{2}\left(1-2{gkQ}\right)\left[\left\langle {x}^{2}\right\rangle \right],\end{array}\end{eqnarray}$
$\begin{eqnarray}\hat{Q}={g}^{2}{k}^{2}Q-2{{gk}}^{3}Q\left[\left\langle {x}^{2}\right\rangle \right]+{k}^{2}\left(1+2{gkQ}\right)\left[{\left\langle x\right\rangle }^{2}\right],\end{eqnarray}$
$\begin{eqnarray}\hat{r}=0,\end{eqnarray}$
$\begin{eqnarray}\hat{R}=0.\end{eqnarray}$
Because $\hat{r}=\hat{R}=0$, we have f(a, b, c) = 0. The free energy is thus reduced to $\begin{eqnarray}-\beta f=\displaystyle \frac{1}{2}Q\hat{Q}-q\hat{q}-\mathrm{ln}\sigma -\displaystyle \frac{{g}^{2}\beta }{2{\sigma }^{2}}Q+\int {\rm{D}}u{\rm{D}}v\mathrm{ln}I,\end{eqnarray}$
where $\begin{eqnarray}\begin{array}{rcl}I & \equiv & \displaystyle \int {\rm{d}}x\exp \left[-\displaystyle \frac{1}{2}\beta \left(\displaystyle \frac{1}{{\sigma }^{2}}+2\eta \right){x}^{2}\right]\\ & & \times \exp \left[+\displaystyle \frac{1}{2}\left(2\hat{q}-\hat{Q}\right){\phi }^{2}(x)+\sqrt{\hat{Q}}u\phi (x)+\displaystyle \frac{g\beta }{{\sigma }^{2}}\sqrt{Q}{vx}\right].\end{array}\end{eqnarray}$
This free energy does not depend on the order parameters r and R anymore. The average energy also yields the following simple form $\begin{eqnarray}\begin{array}{rcl}U & = & \displaystyle \frac{{g}^{2}}{2{\sigma }^{2}}\left(q-{gkQ}(q-Q)\right)+\displaystyle \frac{{gkQ}}{{\sigma }^{4}}\left[{\left\langle x\right\rangle }^{2}\right]\\ & & +\displaystyle \frac{1}{2{\sigma }^{2}}\left(1+2\eta {\sigma }^{2}-{gk}(q-Q)-\displaystyle \frac{2{gkQ}}{{\sigma }^{2}}\right)\left[\left\langle {x}^{2}\right\rangle \right].\end{array}\end{eqnarray}$
Appendix D. Additional experiment results
To illustrate the phase transition in more detail, we choose some curves (γ = 0.2, 0.5, 0.8) and plot them in the 2-dimension plane (figure 8). q and Q are close to zero before the critical point while growing rapidly after the critical point. r and R achieve their maximum values at the critical point.
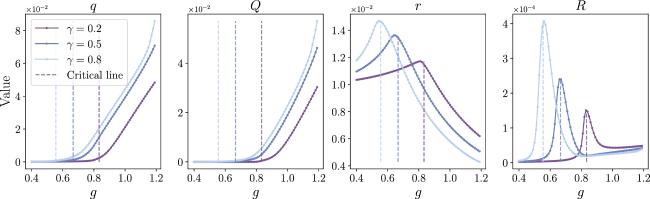
Figure 8. Phase transitions as g increases. We plot three different curves (γ = 0.2, 0.5, 0.8), and different colors represent different γ values. The dashed line represents the DMFT result of critical points in [19]. |
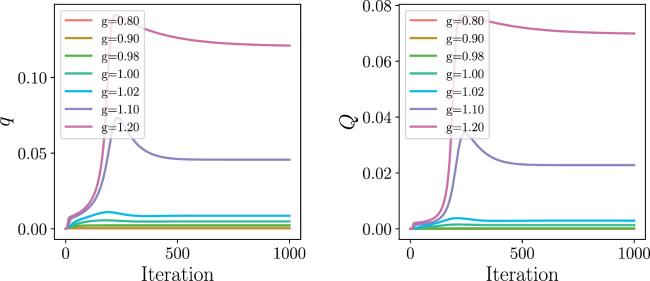
Next, we explore the effect of β in optimizing the energy and the order parameters. When g is close to the critical point, we show how q varies with increasing β (see figure 9 for g = 0.98 and g = 1.0). We observe that q converges more rapidly towards zero when g is below the critical value. When g is approaching the critical value from below, the decaying towards zero becomes much slower, signaling a continuous phase transition. This is also supported by the iteration dynamics of the SDEs (figure 10).
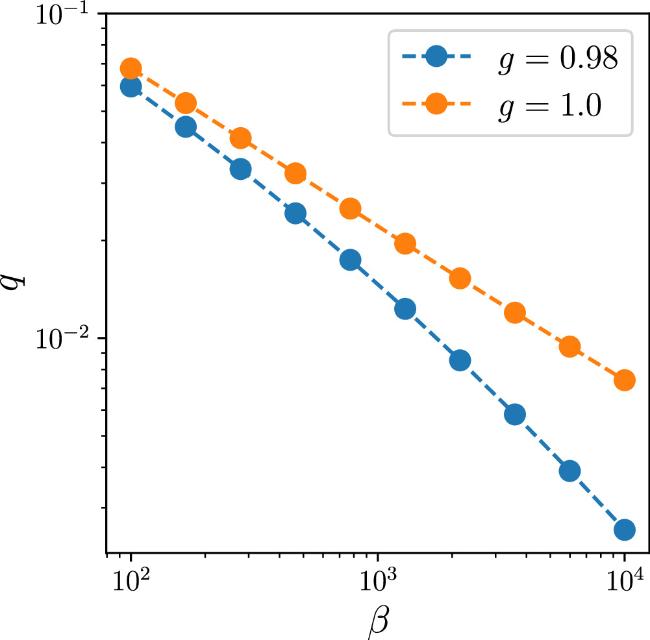
Figure 9. The relationship between q and β when g = 0.98 and g = 1.0 (γ = 0). The blue dots denote g = 0.98 case, and the orange dots denote g = 1.0. Both axes are in the log scale. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 10. The iterative dynamics of q and Q for different values of g. All initial values are set to 10−5 for q and 10−6 for Q. The data points are obtained by using the Algo. |
Appendix E. Numerical details of solving SDEs
The most expensive cost of solving SDEs comes from the double average terms, such as $\left[{\left\langle x\right\rangle }^{2}\right]$ and $\left[{\left\langle \phi \right\rangle }^{2}\right]$, where the outer integral is related to Duv and the inner integral is related dx. These integrals are calculated by the Monte Carlo (MC) method with the important sampling technique [17]. Therefore, we need to generate 100k × 6k Gaussian samples, where 100k MC samples of u and v are used for the outer integral and 6k MC samples of x for each pair of u and v, is used for the inner integral. k here represents 1 000. Note that the inner integral in equation (B3 ) does not contain the Gaussian measure at first sight. However, we can take a reorganization of terms in the effective Hamiltonian. We then get the following equivalent transformation,
$\begin{eqnarray}\left\langle \bullet \right\rangle \equiv \displaystyle \frac{\int {\rm{D}}x{{\rm{e}}}^{\tilde{{ \mathcal H }}(x)}\bullet }{\int {\rm{D}}x{{\rm{e}}}^{\tilde{{ \mathcal H }}(x)}},\end{eqnarray}$
where the Gaussian measure is introduced as ${\rm{D}}x\,\equiv {{\rm{e}}}^{-\displaystyle \frac{1}{2}\beta \left(\tfrac{1}{{\sigma }^{2}}+2\eta \right){x}^{2}}{\rm{d}}x/\sqrt{2\pi }$ and $\begin{eqnarray}\begin{array}{rcl}\tilde{{ \mathcal H }}(x) & \equiv & \displaystyle \frac{1}{2}\left(2\hat{q}-\hat{Q}\right){\phi }^{2}(x)+\left({\kappa }_{1}u+{\kappa }_{2}v\right)\phi (x)\\ & & -\displaystyle \frac{1}{2}\displaystyle \frac{1}{{\sigma }^{2}}{\left({\kappa }_{3}v+(\hat{r}-\hat{R})\phi (x)\right)}^{2}\\ & & +\displaystyle \frac{\sqrt{\beta }}{{\sigma }^{2}}\left({\kappa }_{3}v+(\hat{r}-\hat{R})\phi (x)\right)x.\end{array}\end{eqnarray}$
After an initialization of the order parameters, we complete the double average using the above MC sampling. Then we update the order parameters as follows,
$\begin{eqnarray}{{ \mathcal O }}_{t\,+\,1}=\alpha {{ \mathcal O }}_{t}+(1-\alpha )f({{ \mathcal O }}_{t}),\end{eqnarray}$
where α is the damping parameter (a value close to one) to speed up the convergence. $f({ \mathcal O })$ represents the right-hand-side of equations (B1a ). We stop the iteration when $| {{ \mathcal O }}_{t+1}-{{ \mathcal O }}_{t}| \lt {10}^{-3}$ for all order parameters. We give a pseudocode in Algorithm. 1 for solving the SDEs.
| Input: The initial values of order parameters ${{ \mathcal O }}_{0}$, |
| ${ \mathcal O }\in \{q,Q,r,R\}$ |
| Output: The convergent values of order parameters ${{ \mathcal O }}^{* }$ |
| 1: Generate $100k\times 6k$ Gaussian Monte Carlo samples |
| 2: repeat |
| 3: Calculate all the double averages by the MC method |
| in equation ( |
| 4: Let ${{ \mathcal O }}_{t+1}\leftarrow \alpha {{ \mathcal O }}_{t}+(1-\alpha )f({{ \mathcal O }}_{t})$, where $f({ \mathcal O })$ are the |
| functions specified by the SDEs [see equation ( |
| 5: until $| {{ \mathcal O }}_{t+1}-{{ \mathcal O }}_{t}| \lt {10}^{-3}$ |
| 6: Let ${{ \mathcal O }}^{* }\leftarrow {{ \mathcal O }}_{t}$ |
Appendix F. Zero temperature analysis
Setting β → ∞ , we focus on the ground state of the quasi-potential, which describes the non-equilibrium steady states of equation (1 ). In the zero temperature limit, we have to consider the following scaling behavior guaranteeing a finite value of free energy when β → ∞ [see equation (11 )].
$\begin{eqnarray}\begin{array}{rcl}q-Q & \to & \displaystyle \frac{\chi }{\beta },\\ \hat{Q} & \to & {\beta }^{2}\hat{Q},\\ 2\hat{q}-\hat{Q} & \to & -2\beta \hat{\chi },\\ r & \to & \sqrt{\beta }\tilde{r},\\ R-r & \to & \displaystyle \frac{\xi }{\sqrt{\beta }},\\ \hat{R} & \to & {\beta }^{\tfrac{3}{2}}\kappa ,\\ \hat{r}-\hat{R} & \to & \beta {\rm{\Gamma }},\end{array}\end{eqnarray}$
where the new set of order parameters includes q, χ, $\hat{Q}$, $\hat{\chi }$, $\tilde{r}$, ξ, κ, and Γ, which are all of order one in magnitude.Inserting the above scaling expressions into the free energy [see equation (11 )], which then reads
$\begin{eqnarray}\begin{array}{rcl}-\beta f & = & -\displaystyle \frac{1}{2}\beta \left(-2q\hat{\chi }+\hat{Q}\chi \right)-\beta \left(\tilde{r}{\rm{\Gamma }}-\kappa \xi \right)\\ & & -{g}^{2}\beta \gamma \xi \tilde{r}+\displaystyle \int \left({\rm{D}}u{\rm{D}}v\right)\mathrm{ln}\displaystyle \int {\rm{d}}x{{\rm{e}}}^{\beta {{ \mathcal H }}_{0}(x)},\end{array}\end{eqnarray}$
where $\begin{eqnarray}\begin{array}{rcl}{{ \mathcal H }}_{0}(x) & = & -\eta {x}^{2}-\hat{\chi }{\phi }^{2}(x)\\ & & +\left(\sqrt{\hat{Q}-\displaystyle \frac{{\kappa }^{2}}{{g}^{2}q}}u+\displaystyle \frac{\kappa }{g\sqrt{q}}v\right)\phi (x)\\ & & -\displaystyle \frac{1}{2}\displaystyle \frac{1}{{\sigma }^{2}}{\left(g\sqrt{q}v+{\rm{\Gamma }}\phi (x)-x\right)}^{2}.\end{array}\end{eqnarray}$
In the zero temperature limit β → ∞ , we apply the Laplace method to estimate the following integral
$\begin{eqnarray}\int {\rm{D}}u{\rm{D}}v\mathrm{ln}\int {\rm{d}}x{{\rm{e}}}^{\beta {{ \mathcal H }}_{0}(x)}=\beta \int {\rm{D}}u{\rm{D}}v{{ \mathcal H }}_{0}({x}^{* }),\end{eqnarray}$
where ${x}^{* }={{argmax}}_{x}{{ \mathcal H }}_{0}(x)$. Note that all terms in −βf are proportional to β, and hence the free energy density in the zero temperature limit is given by $\begin{eqnarray}\begin{array}{rcl}-f & = & -\displaystyle \frac{1}{2}\left(-2q\hat{\chi }+\hat{Q}\chi \right)-\left(\tilde{r}{\rm{\Gamma }}-\kappa \xi \right)-{g}^{2}\gamma \xi \tilde{r}\\ & & +\displaystyle \int {\rm{D}}u{\rm{D}}v{{ \mathcal H }}_{0}({x}^{* }).\end{array}\end{eqnarray}$
The new set of order parameters obeys the self-consistent equation making the zero temperature free energy stationary. We thus get the following saddle-point equation:
$\begin{eqnarray}\begin{array}{rcl}q & = & \left[{\phi }^{2}({x}^{* })\right],\\ \chi & = & \displaystyle \frac{{gq}}{\sqrt{{g}^{2}{q}^{2}\hat{Q}-q{\kappa }^{2}}}\left[u\phi ({x}^{* })\right],\\ \hat{Q} & = & \displaystyle \frac{{g}^{2}}{{\sigma }^{4}}\left({g}^{2}q+{{\rm{\Gamma }}}^{2}\left[{\phi }^{2}({x}^{* })\right]+\left[{\left({x}^{* }\right)}^{2}\right]\right.\\ & & \left.-2{\rm{\Gamma }}\left[{x}^{* }\phi ({x}^{* })\right]+2g\sqrt{q}{\rm{\Gamma }}\left[v\phi ({x}^{* })\right]-2g\sqrt{q}\left[{{vx}}^{* }\right]\right),\\ \hat{\chi } & = & \displaystyle \frac{{g}^{2}}{2{\sigma }^{2}}-\displaystyle \frac{{\kappa }^{2}}{2{gq}\sqrt{\hat{Q}{g}^{2}{q}^{2}-q{\kappa }^{2}}}\left[u\phi ({x}^{* })\right]\\ & & +\displaystyle \frac{1}{2\sqrt{q}}\left(\displaystyle \frac{g{\rm{\Gamma }}}{{\sigma }^{2}}+\displaystyle \frac{\kappa }{{gq}}\right)\left[v\phi ({x}^{* })\right]-\displaystyle \frac{1}{{\sigma }^{2}}\displaystyle \frac{g}{2\sqrt{q}}\left[{{vx}}^{* }\right],\\ \tilde{r} & = & -\displaystyle \frac{g\sqrt{q}}{{\sigma }^{2}}\left[v\phi ({x}^{* })\right]-\displaystyle \frac{{\rm{\Gamma }}}{{\sigma }^{2}}\left[{\phi }^{2}({x}^{* })\right]+\displaystyle \frac{1}{{\sigma }^{2}}\left[{x}^{* }\phi ({x}^{* })\right],\\ \xi & = & \displaystyle \frac{\kappa }{g\sqrt{{g}^{2}{q}^{2}\hat{Q}-q{\kappa }^{2}}}\left[u\phi ({x}^{* })\right]-\displaystyle \frac{1}{g\sqrt{q}}\left[v\phi ({x}^{* })\right],\\ \kappa & = & {g}^{2}\gamma \tilde{r},\\ {\rm{\Gamma }} & = & -{g}^{2}\gamma \xi ,\end{array}\end{eqnarray}$
where $\left[\bullet \right]\equiv \int {\rm{D}}u{\rm{D}}v$ as before, and to estimate this average, we first generate M = 5 × 106 Monte Carlo samples ${\{({u}_{i},{v}_{i})\}}_{i\,=\,1}^{M}$, for each of them we find the global maximum of ${{ \mathcal H }}_{0}(x)$, i.e., x*. All these values corresponding to the maxima [for each pair of (u, v)] are further used to complete the calculation of the order parameter for one round. The codes of this paper are released on the GitHub link [47].